
一切知识都从一个小问题开始:
给定一些命令,如set, setbit, setnx, strlen,get, getbit, exists 实现自动补全功能,例如输入se, 提示set, setbit, setnx
此视频为录制的redis客户端命令操作,很显然redis-cli就实现了这样的功能
假设我们运用现有的知识,应当如何解决这个问题呢?
-
MySQL
直接使用MySQL的 like 'se%' 命令即可,确实,作为一个每天沉迷业务的程序员很快就能想到这样的方式,但是就这么个小问题,需要使用上MySQL吗,不至于不至于

-
B+Tree
我们知道,MySQL的数据结构使用的是B+Tree, (什么?你不知道?现在你知道了吧「滑稽.jpg」),它构建好后就像这样
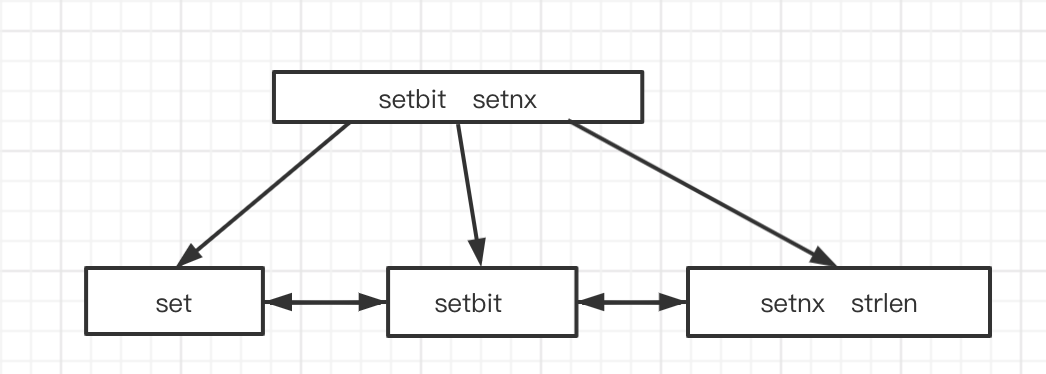
查找过程如下:
se -> 转ASCII码, 与根结点比较,小于setbit的ASCII码,走左边,定位到set,依次从左往右遍历,一一比较,输出所有前缀为se的字符串。
-
有序数组
虽然b+数的查找效率确实很好,但是构建过程却是比较复杂的,有没有一个更加简单的数据结构呢?通过分析b+树的解决方式,我们可以发现,这里用到了两个特性:二分,有序,通过二分的方式快速定位到最小结点,就能有序的从左往右取出值了,考虑到我们的命令不是很多,如果我们只使用有序这个特性会怎样呢?就像这样:
[exists, get, getbit, set, setbit, setnx, strlen]查找过程如下:
输入se,从左往右遍历匹配,找到符合se前缀的值set开始输出,直到遇到不符合的值strlen,停止遍历
这样的方式就非常简单了,但是效率确实不如b+tree
所以到底有没有更加好的方式呢?我们先来总结一下,更加好的方式需要满足的特性:
- 二分,可以快速定位
- 有序,顺序的取出符合要求的元素
- 简单,结构简单
其实,这就是一颗有序的且结构简单的树(最常见的能二分的结构其实就是树了),也就是本次的主角:Trie树
概念
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
构建过程
根据维基百科的概念,我们可以总结出以下特性
- 根节点对应空字符串。
- 一个节点的所有子孙都有相同的前缀。
- 不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
所以我们将set, setbit, setnx, strlen, get, getbit, exists构建好后,它的样子如图
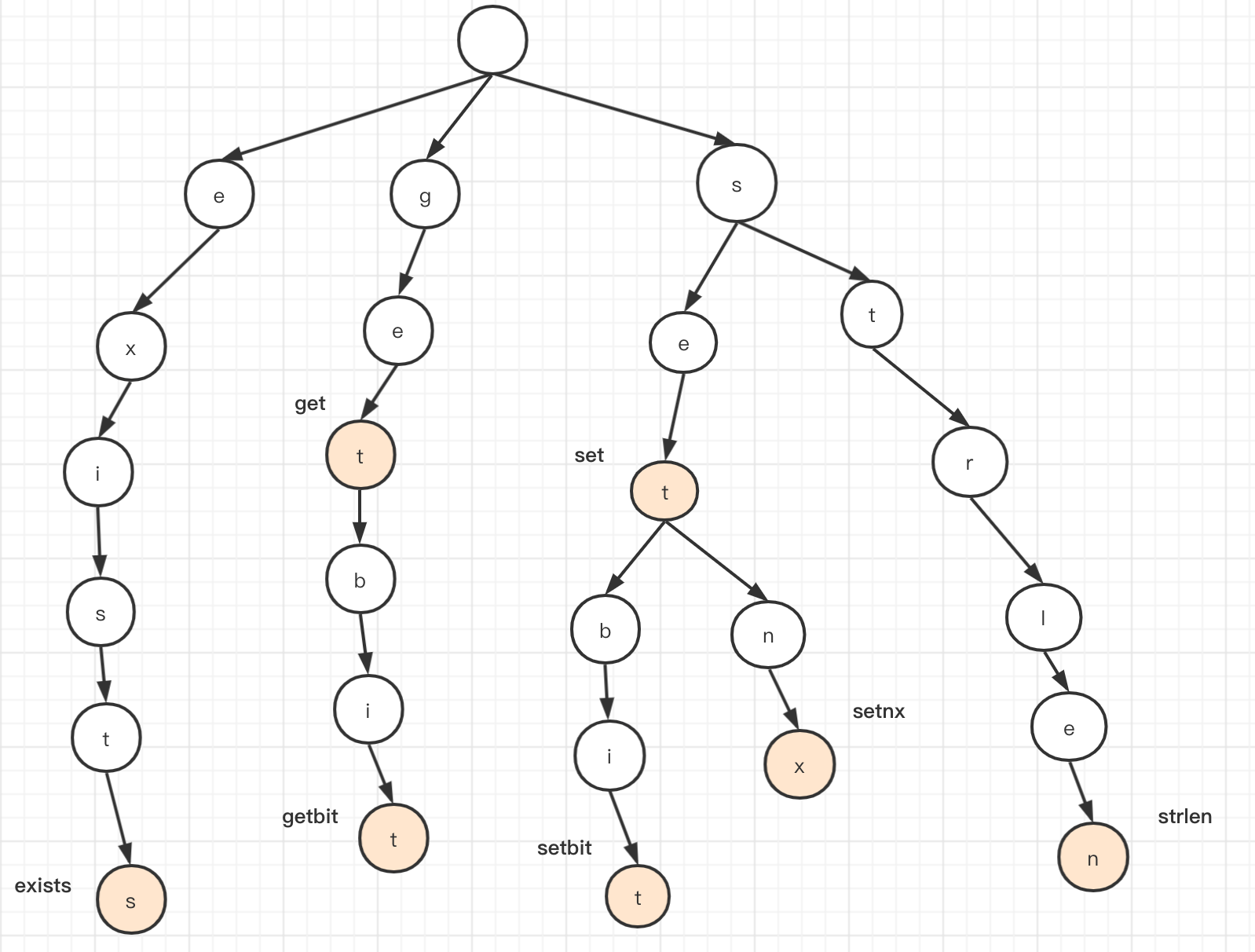
可以对比一下这张图和几个特性
Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起
我给大家介绍一下这颗树
- 上面的黄色结点表示终点(构建时打上标记),指一个完整的字符串,如第二条链中的get,getbit, 一般情况下除了黄色结点是不会有值的,这里只是为了更好的展现出来。
- 树的每一层都是按照字母顺序(a-z)从左到右排列
那么,我先现在就尝试查找一个字符串是否存在,比如查找get
- g -> 定位到 g字母对应的叉 -getbit
- e -> 定位到 -etbit
- t -> 判断t点是否是终点 -> 是 -> 存在
时间复杂度为O(n) n为需要查找的字符串长度
为什么是O(n)? get定位了3次,难道每次定位一个字符都是O(1)? 怎么做到的?
查询前缀同理
所以我们想要做一个自动补全功能时,比如输入se,流程如下:
s-> 找到s对应的叉e-> 找到s链的e结点对应的叉- 遍历e结点下的整颗树
- 当遇见黄点时输出该值
到这里,原理相信大家都已经明白了,那么代码应当如何实现呢?
代码
树的实现无非两种,数组 或者 链表,通过观察上面的树,可以发现,每一层的结点最多有26个(a-z),我们可以直接开辟26个长度的数组存储这些结点,又因为每一层的字符是有序的,于是定位一个字符c的时候只需要c-'a'就能得出下标,如定位g
'g' - 'a' = 6
数据结构如下:
public class TrieNode {
// 是否是终点
boolean isEnd;
// 字符串的值,isEnd = true 时才有
String value;
// 子结点
TrieNode[] childrenNodes = new TrieNode[26];
}
完整代码:
public class TrieTree {
TrieNode trieNode;
public TrieTree() {
this.trieNode = new TrieNode();
}
/**
* 增加一个结点
*
* @param word 单词
*/
public void add(String word) {
char[] chars = word.toLowerCase().toCharArray();
TrieNode next = trieNode;
for (char c : chars) {
TrieNode trieNode = next.childrenNodes[c - 'a'];
if (trieNode == null) {
trieNode = new TrieNode();
next.childrenNodes[c - 'a'] = trieNode;
}
next = trieNode;
}
next.isEnd = true;
next.value = word;
}
/**
* 查询单词是否存在
*
* @param word 单词
* @return 是否存在
*/
public boolean search(String word){
TrieNode trieNode = searchNode(word);
return trieNode != null && trieNode.isEnd;
}
/**
* 判断前缀是否存在
*
* @param prefix 前缀
* @return 是否存在
*/
public boolean starsWith(String prefix){
return searchNode(prefix) != null;
}
/**
* 查询结点
*
* @param word 单词
* @return 结点
*/
private TrieNode searchNode(String word){
char[] chars = word.toLowerCase().toCharArray();
TrieNode next = trieNode;
for (char c : chars) {
TrieNode trieNode = next.childrenNodes[c - 'a'];
if (trieNode == null) {
return null;
}
next = trieNode;
}
return next;
}
/**
* 自动补全
* @param prefix 前缀
* @param list 结果集
*/
public void autocomplete(String prefix, List<String> list){
TrieNode trieNode = searchNode(prefix);
if (trieNode != null) {
autocomplete(trieNode, list);
}
}
private void autocomplete(TrieNode trieNode, List<String> list){
TrieNode[] trieNodes = trieNode.childrenNodes;
for (TrieNode node : trieNodes) {
if (node != null) {
if (node.isEnd) {
list.add(node.value);
}
autocomplete(node, list);
}
}
}
public class TrieNode {
// 是否是终点
boolean isEnd;
// 字符串的值,isEnd = true 时才有
String value;
// 子结点
TrieNode[] childrenNodes = new TrieNode[26];
}
public static void main(String[] args) {
TrieTree trieTree = new TrieTree();
trieTree.add("apple");
trieTree.add("apply");
trieTree.add("application");
System.out.println(trieTree.search("apple"));
System.out.println(trieTree.search("app"));
System.out.println(trieTree.starsWith("app"));
List<String> list = new ArrayList<>();
trieTree.autocomplete("app", list);
System.out.println(list);
}
}
测试结果
true
false
true
[apple, application, apply]
小结
本篇介绍了什么是Trie树,以及通过Trie树如何实现一个自动补全功能,下面我们计算一下它的时间复杂度和空间复杂度
时间复杂度:O(n) n为需要查找的字符串长度
空间复杂度:26^n
26^n这个字眼着实令人咂舌,这也是大家常说trie树是一颗空间换时间的树,而且这还只是只有英文字符的情况,倘若加上数字呢,中文呢?
那么有没有什么优化的办法呢?
有的,比如查看上图就能发现,虽然把所有前缀相同的单词合并到了一起,但是还是有很多重复的,比如 setbit, getbit, 这两个单词出入开头的s和g不同,其他的都是相同的,如果我们能把他们共用,岂不也能大大缩小空间,如何实现,下次再说!
Trie树的应用场景
- 词语查找,比如在中文分词器中,就可以使用用户字典构建一颗Trie树,使用时输入句子进行匹配分词
- 自动补全
- 拼写检查