
前言
在今天,依然有许多人对循环依赖有着争论,也有许多面试官爱问循环依赖的问题,更甚至是在Spring中只问循环依赖,在国内,这彷佛成了Spring的必学知识点,一大特色,也被众多人津津乐道。而我认为,这称得上Spring框架里众多优秀设计中的一点污渍,一个为不良设计而妥协的实现,要知道,Spring整个项目里也没有出现循环依赖的地方,这是因为Spring项目太简单了吗?恰恰相反,Spring比绝大多数项目要复杂的多。同样,在Spring-Boot 2.6.0 Realease Note中也说明不再默认支持循环依赖,如要支持需手动开启(以前是默认开启),但强烈建议通过修改项目来打破循环依赖。
本篇文章我想来分享一下关于我对循环依赖的思考,当然,在这之前,我会先带大家温故一些关于循环依赖的知识。
依赖注入
由于循环依赖是在依赖注入的过程中发生的,我们先简单回顾一下依赖注入的过程。
案例:
@Component
public class Bar {
}
@Component
public class Foo {
@Autowired
private Bar bar;
}
@ComponentScan(basePackages = "com.my.demo")
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Main.class);
context.getBean("foo");
}
}
以上为一个非常简单的Spring入门案例,其中Foo注入了Bar, 该注入过程发生于context.getBean("foo")中。
过程如下:
1、通过传入的"foo", 查找对应的BeanDefinition, 如果你不知道什么是BeanDefinition,那你可以把它理解成封装了bean对应Class信息的对象,通过它Spring可以得到beanClass以及beanClass标识的一些注解。
2、使用BeanDefinition中的beanClass,通过反射的方式进行实例化,得到我们所谓的bean(foo)。
3、解析beanClass信息,得到标识了Autowired注解的属性(bar)
4、使用属性名称(bar),再次调用context.getBean('bar'),重复以上步骤
5、将得到的bean(bar)设值到foo的属性(bar)中
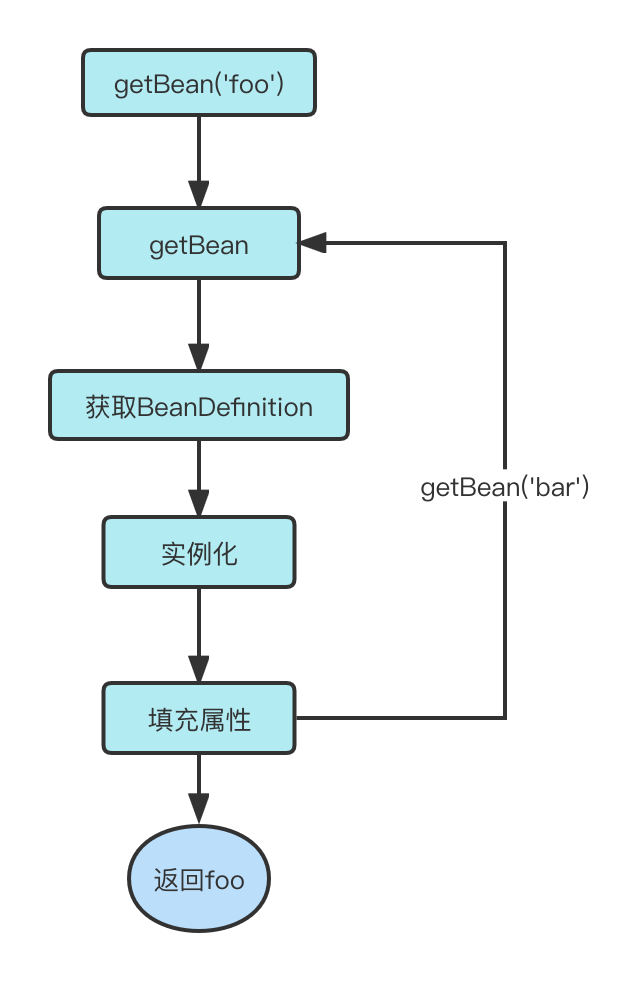
以上为简单的流程描述
什么是循环依赖
循环依赖其实就是A依赖B, B也依赖A,从而构成了循环,从以上例子来讲,如果bar里面也依赖了foo,那么就产生了循环依赖。

Spring是如何解决循环依赖的
getBean这个过程可以说是一个递归函数,既然是递归函数,那必然要有一个递归终止的条件,在getBean中,很显然这个终止条件就是在填充属性过程中有所返回。那如果是现有的流程出现Foo依赖Bar,Bar依赖Foo的情况会发生什么呢?
1、创建Foo对象
2、填充属性时发现Foo对象依赖Bar
3、创建Bar对象
4、填充属性时发现Bar对象依赖Foo
5、创建Foo对象
6、填充属性时发现Foo对象依赖Bar....
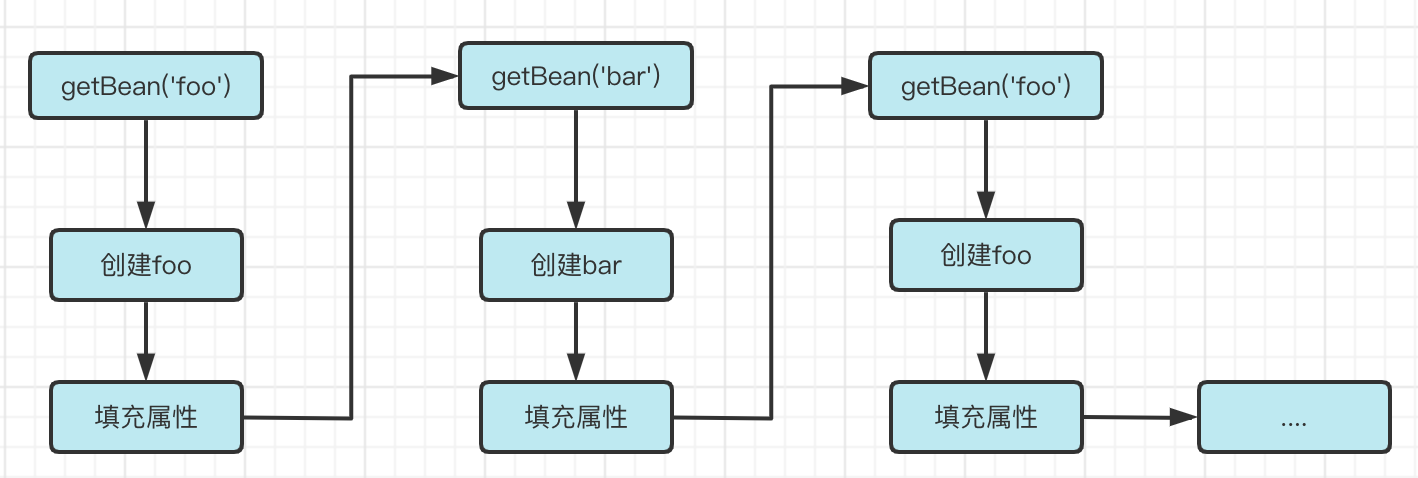
很显然,此时递归成为了死循环,该如何解决这样的问题呢?
添加缓存
我们可以给该过程添加一层缓存,在实例化foo对象后将对象放入到缓存中,每次getBean时先从缓存中取,取不到再进行创建对象。
缓存是一个Map,key为beanName, value为Bean,添加缓存后的过程如下:
1、getBean('foo')
2、从缓存中获取foo,未找到,创建foo
3、创建完毕,将foo放入缓存
4、填充属性时发现Foo对象依赖Bar
5、getBean('bar')
6、从缓存中获取bar,未找到,创建bar
7、创建完毕,将bar放入缓存
8、填充属性时发现Bar对象依赖Foo
9、getBean('foo')
10、从缓存中获取foo,获取到foo, 返回
11、将foo设值到bar属性中,返回bar对象
12、将bar设置到foo属性中,返回
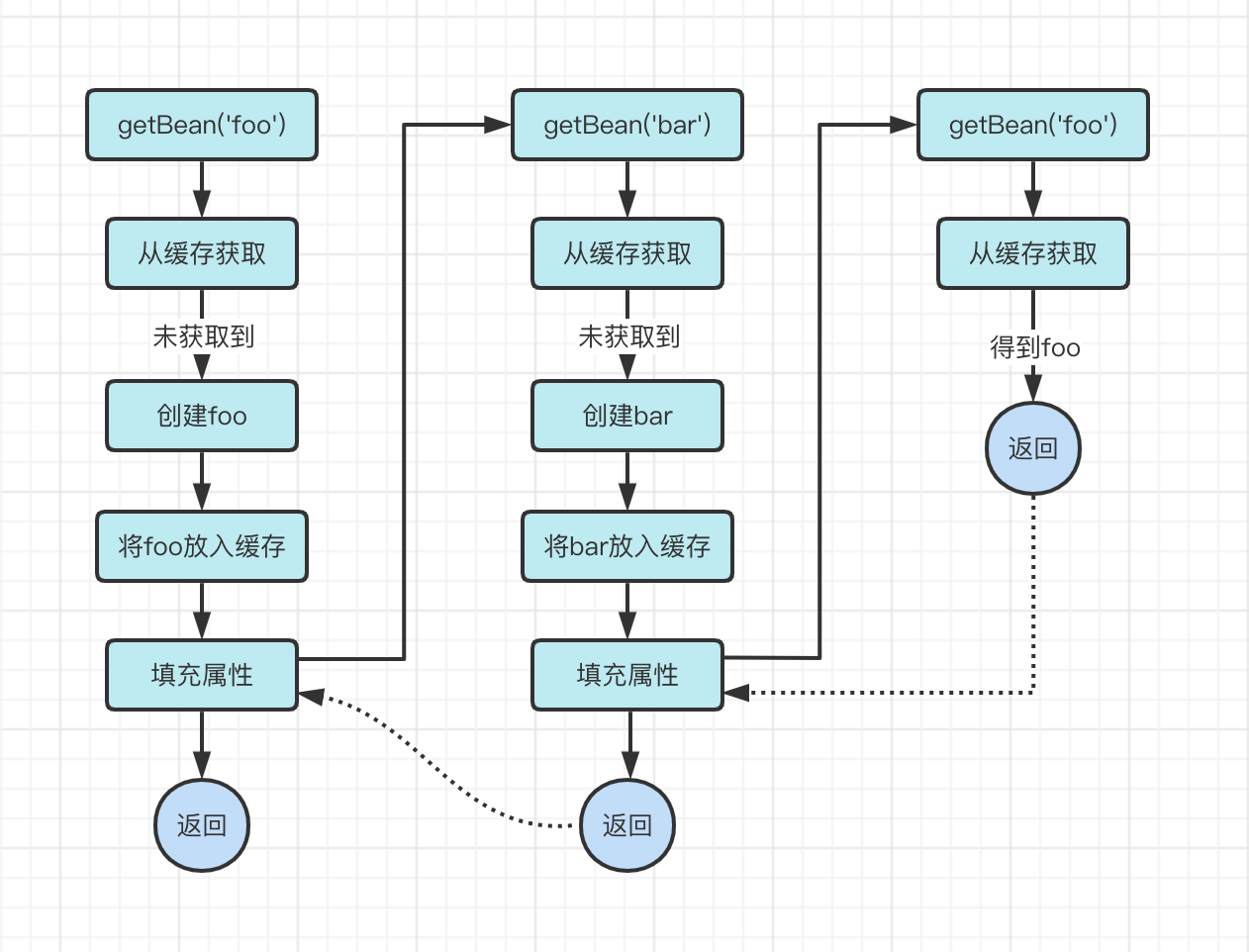
以上流程在添加一层缓存之后我们发现确实可以解决循环依赖的问题。
多线程出现空指针
你可能注意到了, 当出现多线程情况时,这一设计就出现了问题。
我们假设有两个线程正在getBean('foo')
1、线程一正在运行的代码为填充属性,也就是刚刚将foo放入缓存之后
2、线程二稍微慢一些,正在运行的代码是:从缓存中获取foo
此时,我们假设线程一挂起,线程二正在运行,那么它将执行从缓存中获取foo这一逻辑,这时你就会发现,线程二得到了foo,因为线程一刚刚将foo放入了缓存,而且此时foo还没有被填充属性!
如果说线程二得到这个还没有设值(bar)的foo对象去使用,并且刚好用了foo对象里面的bar属性,那么就会得到空指针异常,这是不能为允许的!
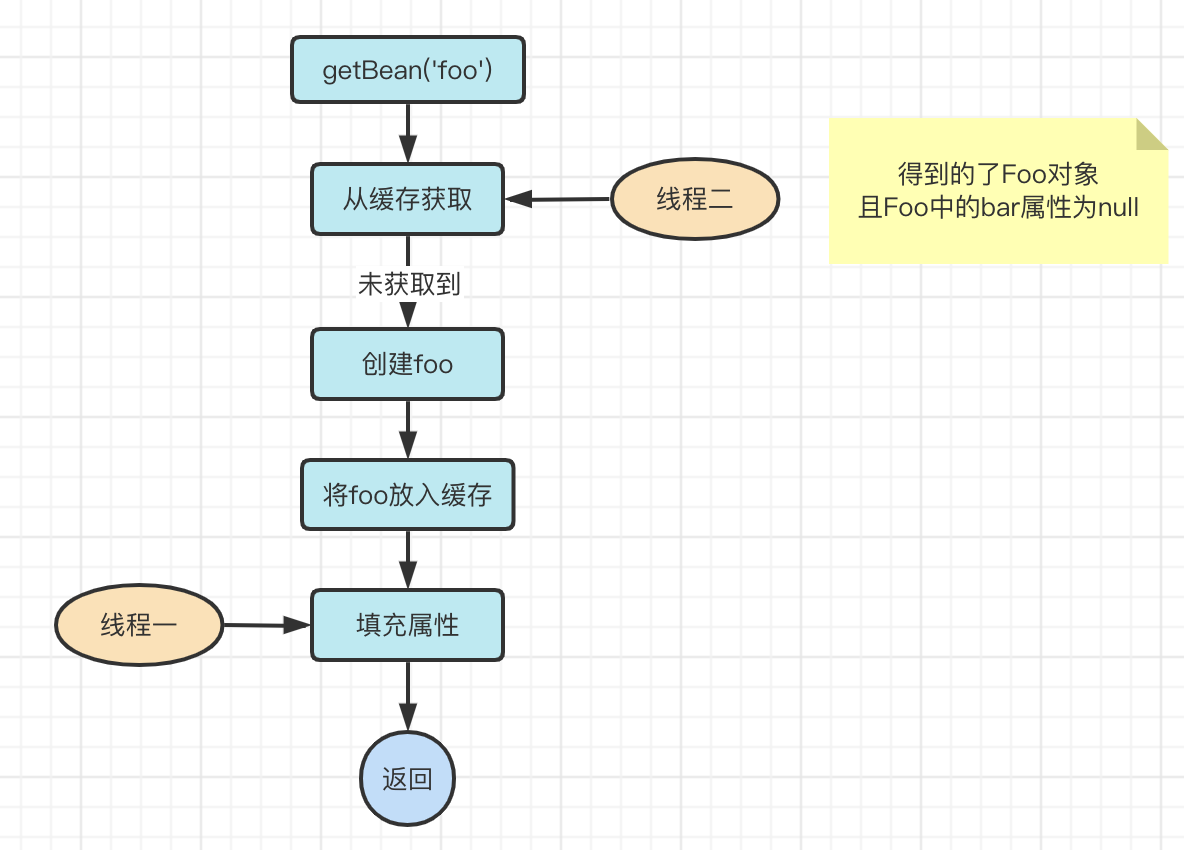
那么我们又当如何解决这个新的问题呢?
加锁
解决多线程问题最简单的方式便是加锁。
我们可以在【从缓存获取】前加锁,在【填充属性】后解锁。
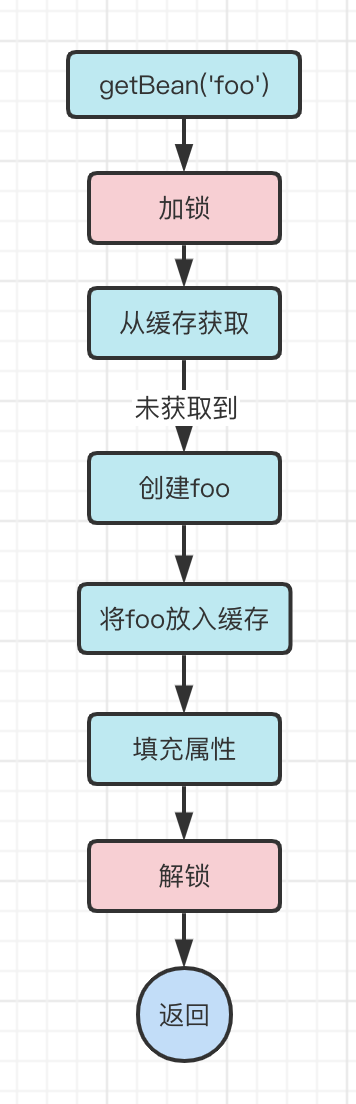
如此,线程二就必须等待线程一完成整个getBean流程之后才在缓存中获取foo对象。
我们知道加锁可以解决多线程的问题,但同样也知道加锁会引起性能问题。
试想,加锁是为了保证缓存里的对象是一个完备的对象,但如果当缓存里的所有对象都是完备的了呢?或者说有部分对象已经是完备了的呢?
假设我们有A、B、C三个对象
1、A对象已经创建完毕,缓存中的A对象是完备的
2、B对象还在创建中,缓存中的B对象有些属性还没填充完毕
3、C对象还未创建
此时我们想要getBean('A'), 那我们应该期望什么?我们是否期望直接从缓存中获取到A对象返回?或者还是等待获取锁之后才能得到A对象?
很显然我们更加期望直接获取到A对象返回就可以了,因为我们知道A对象是完备的,不需要去获取锁。
但以上的设计也很显然无法达到该要求。
二级缓存
以上问题其实可以简化成如何将完备对象和不完备的对象区分开来?因为只要我们知道这个是完备对象,那么直接返回,如果是不完备的对象,那么就需要获取锁。
我们可以这样,再加一级缓存,第一级缓存存放完备对象,第二级缓存存放不完备的对象,由于此类对象是在Bean刚创建时放入缓存中的,所以我们这里把它称作早期对象。
此时,当我们需要获取A对象时,我们只需判断第一级缓存有没有A对象,如果有,说明A对象是完备的,可直接返回使用,如果没有,说明A对象可能还没创建或者是创建中,就继续加锁-->从二级缓存获取对象-->创建对象的逻辑
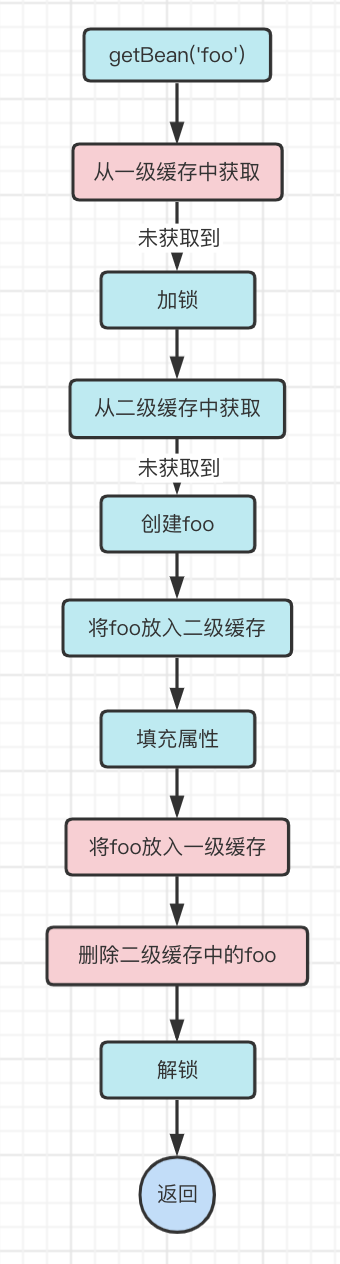
此时流程如下:
1、getBean('foo')
2、从一级缓存中获取foo,未获取到
3、加锁
4、从二级缓存中获取foo,未获取到
5、创建foo对象
6、将foo对象放入二级缓存
7、填充属性
8、将foo对象放入一级缓存,此时foo对象已经是个完备对象了
9、删除二级缓存中的foo对象
10、解锁返回
基于现有流程,我们再来模拟一下循环依赖时的情况
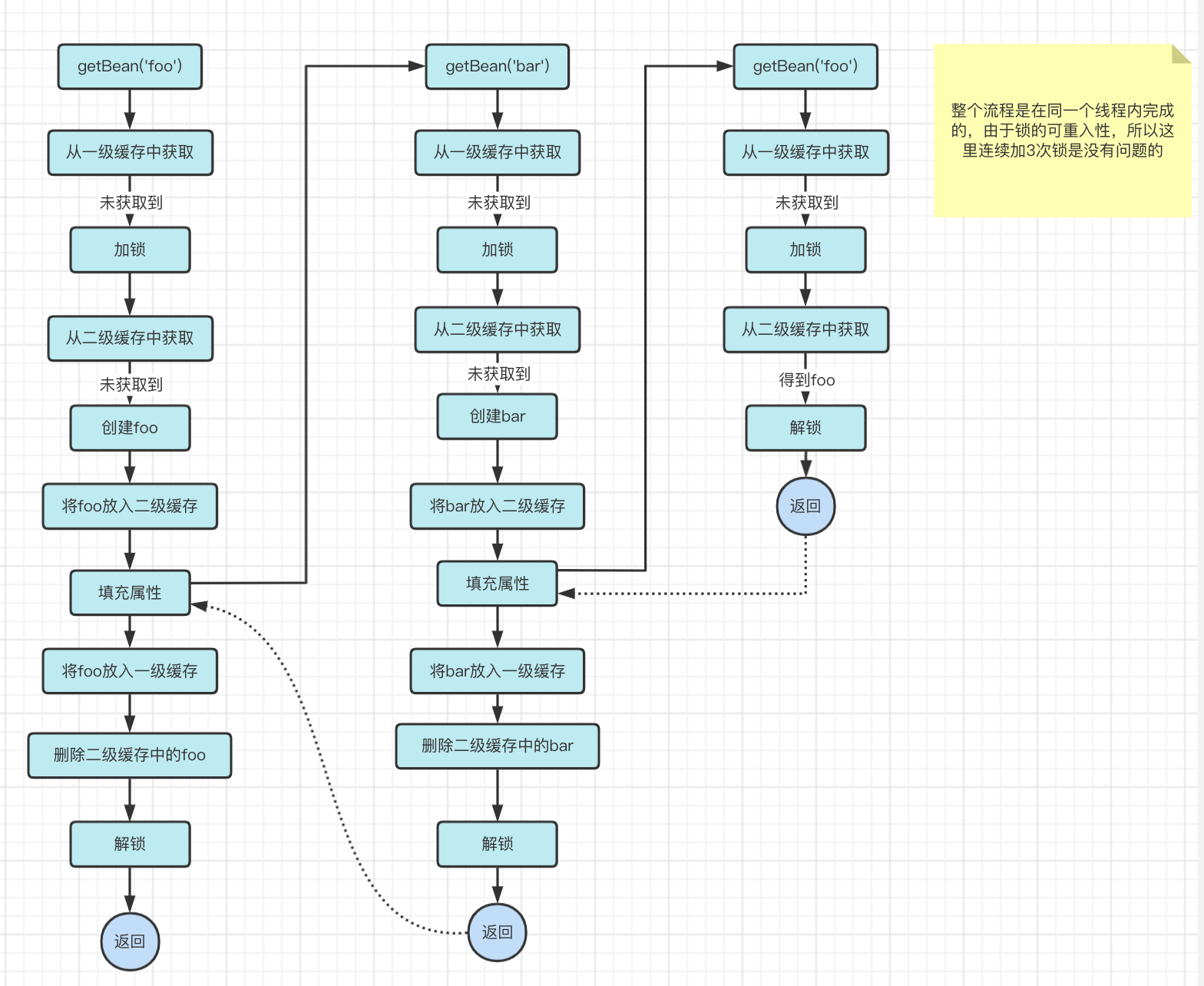
现在,既能解决对象的完备性问题,又能满足我们的性能要求。perfect!
代理对象
要知道,Java里不仅有普通对象,还有代理对象,那么创建代理对象发生循环依赖时是否能够满足要求呢?
我们先来了解一下代理对象是什么时候创建的?
在Spring中,创建代理对象逻辑是在最后一步,也就是我们常常说的【初始化后】
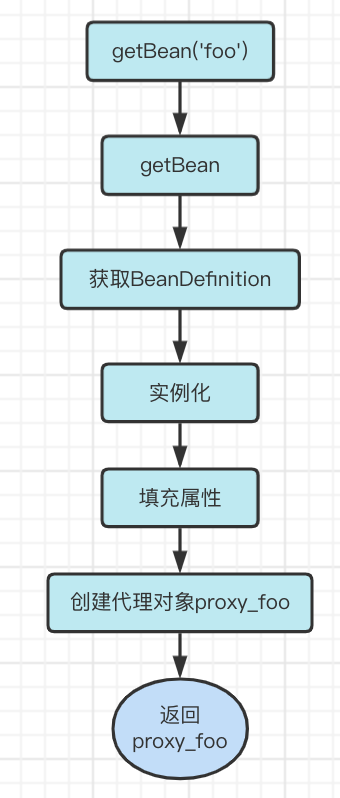
现在,我们尝试把这部分逻辑加入到之前的流程中
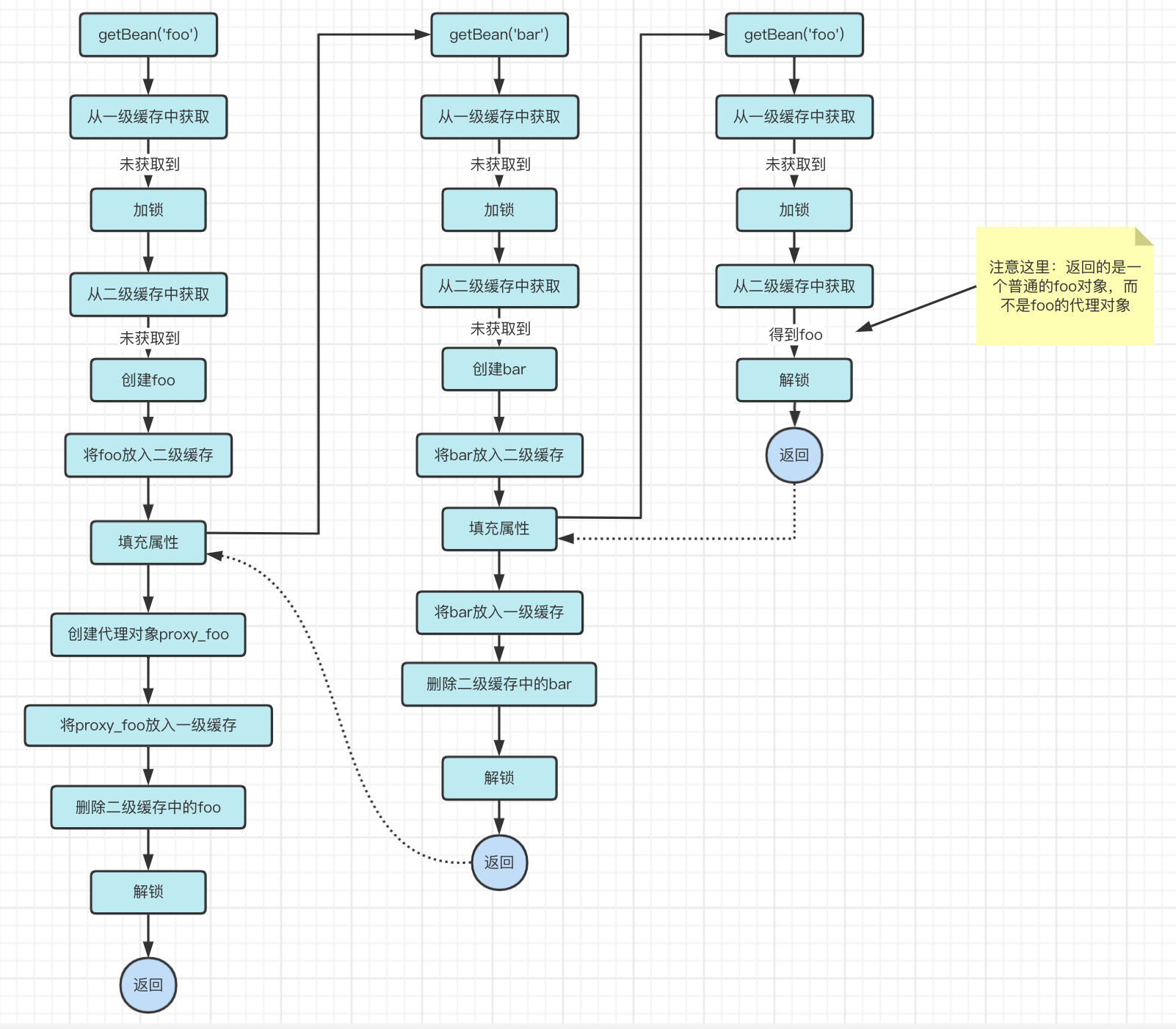
显而易见,最后的foo对象实际已经是个代理对象了,但bar依赖的对象依旧是个普通的foo对象!
所以,当出现代理对象循环依赖时,之前的流程并不能满足要求!
那么这个问题又应当如何解决呢?
思路
问题出现的原因就在于bar对象去获取foo对象时,从二级缓存中得到的foo对象是个普通的对象。
那么有没有办法在这里添加一些判断,比如说判断foo对象是不是要进行代理,如果是的话就去创建foo的代理对象,然后将代理对象proxy_foo返回。
我们先假设这个方案是可行的,再来看有没有其他的问题
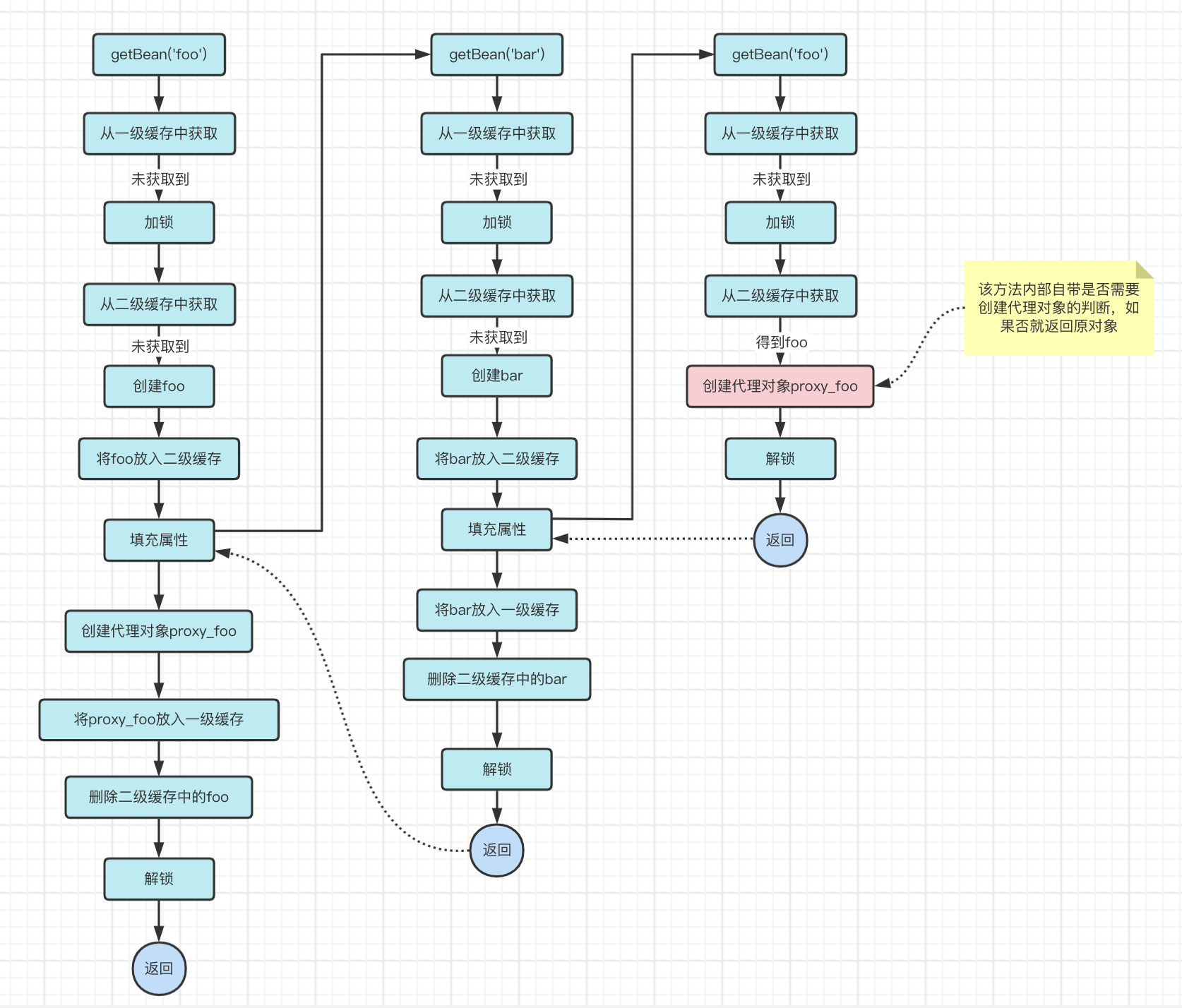
根据流程图我们可以发现出一个问题:创建了两次proxy_foo!
1、getBean('foo')流程中,填充属性之后创建了一次proxy_foo
2、getBean('bar')的填充属性时,从缓存中获取foo时,也创建了一次proxy_foo
而这两个proxy_foo是不相同的!虽然proxy_foo中引用的foo对象是相同的,但这也是不可接受的。
这个问题又当如何解决?
三级缓存
我们知道这两次创建的proxy_foo是不相同的,那么程序应当如何知道呢?也就是说,我们如果可以加一个标识,标识这个foo对象已经被代理过了,让程序直接使用这个代理的就可以了,不要再去创建代理了。是不是就解决这个问题了呢?
这个标识可不是什么flag=ture or false之类的,因为就算程序知道foo已经被代理过了,那程序还是得把proxy_foo拿到才行,也就是说,我们还得找个地方把proxy_foo存起来。
这个时候我们就需要再加一级缓存。
逻辑如下:
1、当从缓存中获取foo时,且foo被代理了之后,就将proxy_foo放入这一级缓存中。
2、在getBean('foo')流程中,创建代理对象时,先在缓存中查看是否有代理对象,如果有则使用该代理对象
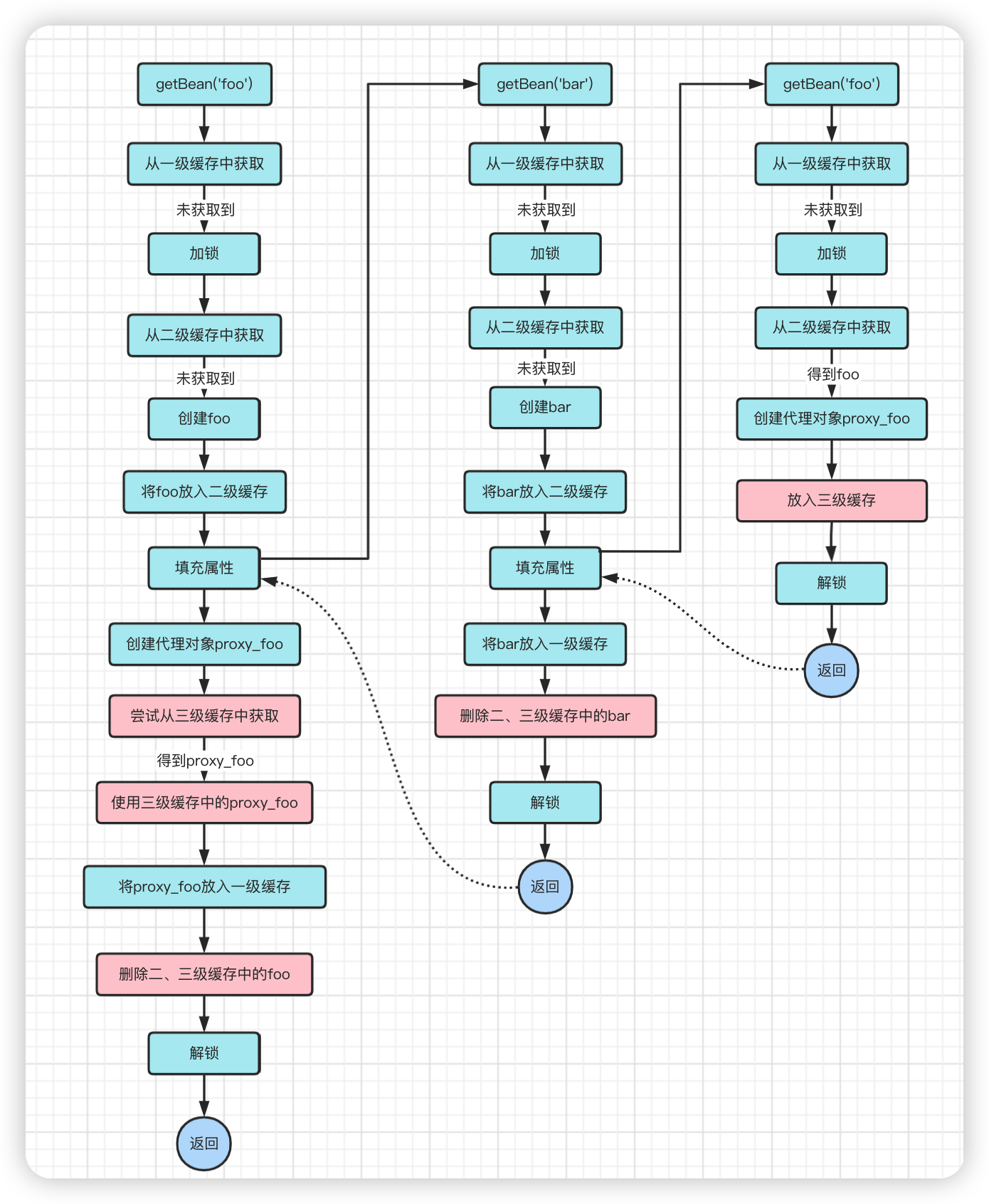
这里你可能会有疑问:不是说先判断三级缓存有没有,没有再去创建proxy_foo嘛?怎么不管有没有都去创建?
是的,这里不管如何都去创建了proxy_foo,只是最后判断三级缓存有没有,有的话就使用三级缓存里的,之前创建的proxy_foo就不要了。
原因是这样的,我们知道创建代理对象的逻辑是在Bean【初始化后】这一流程当中的某个后置处理器当中完成的,而后置处理器是可以由用户自定义实现的,那么反过来说就表示Spring是无法控制这一部分逻辑的。
我们可以这样假设,我们自己也实现了一个后置处理器,这个处理器的作用不是创建代理对象proxy_foo,而是把foo替换成dog, 如果按之前的想法(只判断是否为代理对象)你就会发现这样的问题:getBean('foo')返回的是dog,但是bar对象依赖的是foo。
但是如果我们将【创建代理对象】这一逻辑看成只是众多后置处理器中的一个实现。
1、在从缓存中取foo时,调用一系列的后置处理器,然后将后置处理器返回的最终结果放入三级缓存。
2、在getBean('foo')时,同样调用一系列的后置处理器,然后从三级缓存获取foo对应的对象,得到了就使用它,否则使用后置处理器返回结果。
你就会发现,随便你怎么折腾,getBean('foo')返回的对象与bar对象依赖的foo永远是同一个对象。
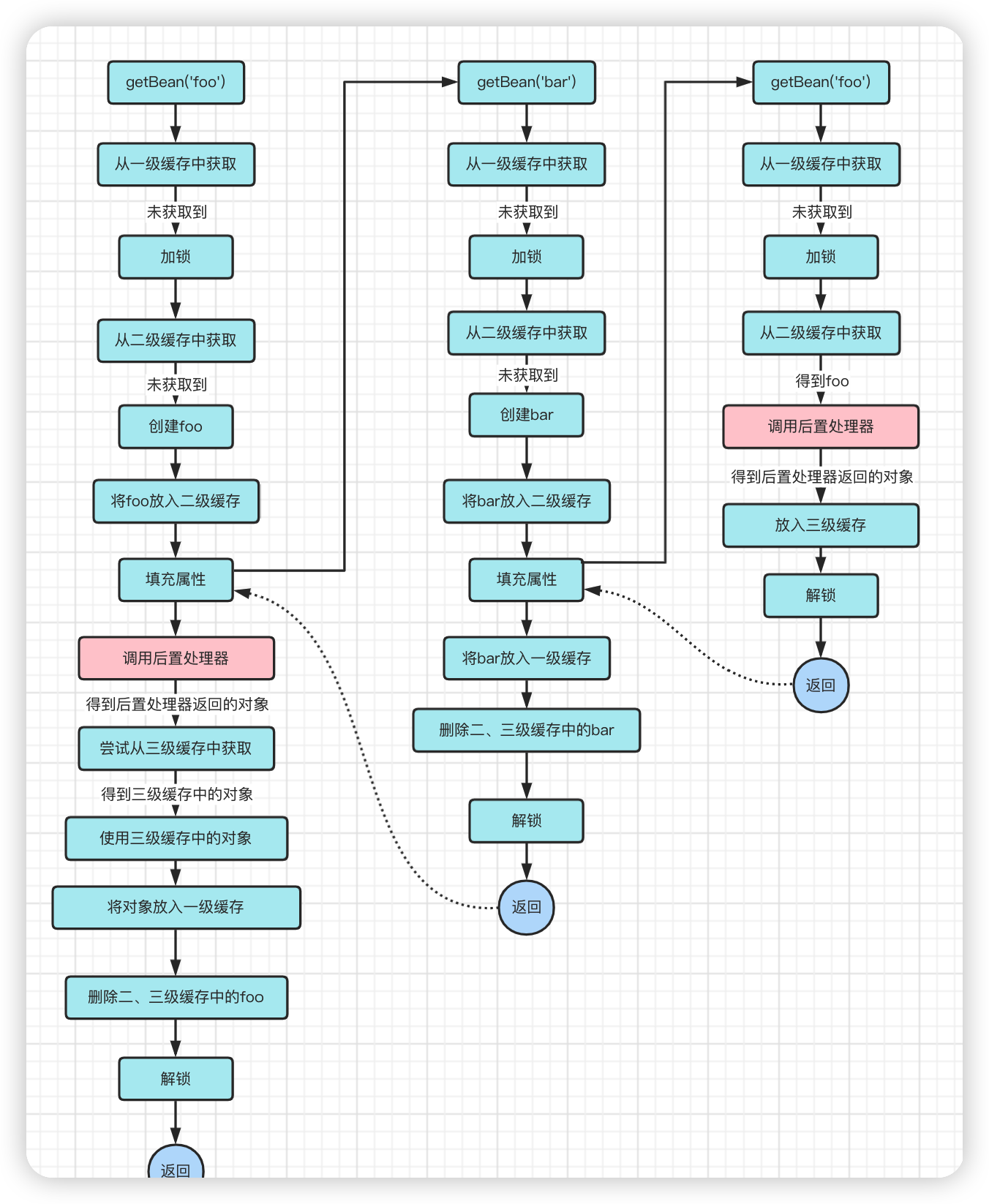
以上即为Spring对于循环依赖的解决方案
我对Spring这部分设计的思考
先总体回顾一下Spring的设计,Spring中采用了三级缓存
1、第一级缓存存放完备的bean对象
2、第二级缓存存放的是匿名函数
3、第三级缓存存放的是从第二级缓存中匿名函数返回的对象
是的,Spring将我们说的[从二级缓存中获取foo, 调用后置处理器]这两个步骤直接做成了一个匿名函数
它的结构如下:
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
@FunctionalInterface
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}
函数内容即为调用一系列后置处理器
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
对于这部分设计,一直存在着一些争议:Spring中到底使用几级缓存可以解决循环依赖?
观点一
普通对象发生循环依赖时二级缓存即可以解决,但代理对象发生循环依赖时需要三级缓存才可以
这也算是一个普遍的观点
这个观点的角度是用二级缓存时,发生循环依赖会不会出bug,认为是普通对象不会,代理对象会。
换句话说:在发生多循环依赖时,多次从缓存中获取对象,每次得到的对象是否相同?
举例来说,A对象依赖B对象,B对象依赖A对象和C对象,C对象依赖A对象。
getBean('A')流程如下
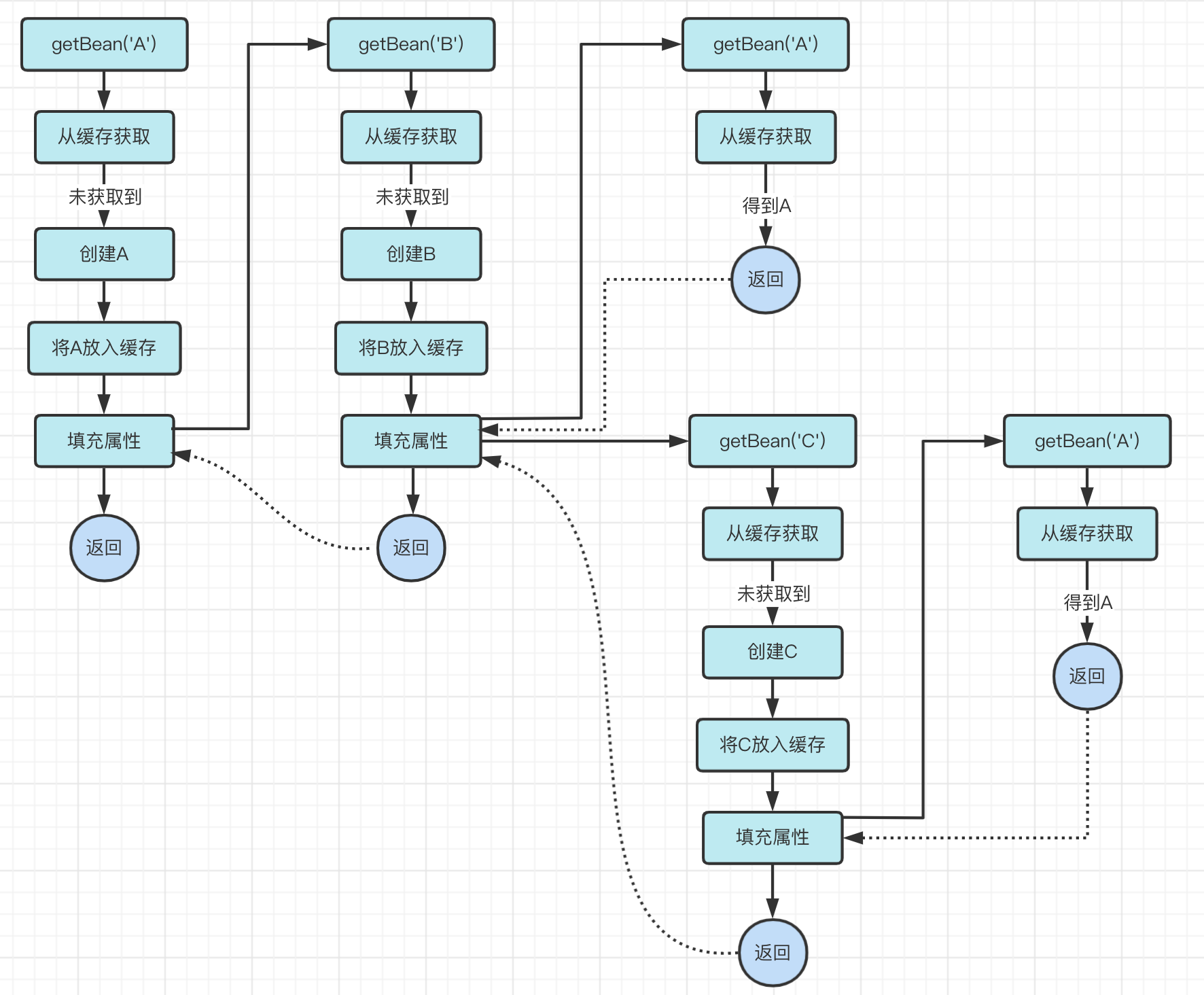
在该流程中,A对象从缓存中获取了两次。
现在,我们结合从缓存中获取对象的过程来思考一下。
当只有二级缓存时的逻辑:
1、调用二级缓存中的匿名函数获取对象
2、返回对象
假设匿名函数中返回原对象,没有创建代理逻辑——这里严格来说是没有后置处理器的逻辑
那么每次【调用二级缓存中的匿名函数获取对象】时返回的A对象都是同一个。
所以得出普通对象在只有二级缓存时没有问题。
假设匿名函数中会触发创建代理的逻辑,匿名函数返回的是代理对象。
那么每次【调用二级缓存中的匿名函数获取对象】时都会创建代理对象。
每次创建的代理对象都是个新对象,故每次返回的A对象都不是同一个。
所以得出代理对象在只有二级缓存时会出现问题。
那么为什么三级缓存可以呢?
三级缓存时的逻辑:
1、先尝试从三级缓存中获取,未获取到
2、调用二级缓存中的匿名函数获取对象
3、将对象放入三级缓存
4、删除二级缓存中的匿名函数
5、返回对象
所以在第一次从缓存获取时会调用匿名函数创建代理对象,往后每次获取时都是直接从第三级缓存取出返回。
综上所述,该观点是占得住脚的。
但我更希望这个观点换个更严谨说法:当每次匿名函数返回的对象是一致时,二级缓存足以;当每次匿名函数返回的对象不一致时,需要有第三级缓存
观点二
该观点也是我自己的观点:从设计的角度出发,只有三级缓存才能保证框架的扩展性和健壮性。
当我们回顾观点一的结论,你就会发现一个十分矛盾的地方:Spring如何才能得知匿名函数返回的对象是一致的?
匿名函数中的逻辑是调用一系列的后置处理器,而后置处理器是可自定义的。
意思就是匿名函数返回了什么,这件事本身就不受Spring所控制。
这时我们再借用三级缓存看这个问题,就会发现:无论匿名函数返回的对象是否一致,三级缓存都能有效的解决循环依赖的问题。
从设计来看,三级缓存的设计是可以包含二级缓存所达到的需求的。
所以我们可以得出:使用三级缓存的设计将比二级缓存的设计有更好的扩展性和健壮性。
如果用观点一的看法去设计Spring框架,那得加一大堆逻辑判断,如果用观点二,那只需加一层缓存。
小结
本篇文章的初衷是想写我对Spring循环依赖的思考,但为了能够说清楚这件事,还是详细的描述了Spring解决循环依赖的设计。
以至于最后我想表达自己的思考时,只有寥寥几句,因为大部分思考我已写在了【Spring是如何解决循环依赖的】章节。
最后,希望大家有所收获,如果有疑问可找我询问,或者在评论区留下你的思考。
如果我的文章对你有所帮助,还请帮忙点赞、关注、转发一下,你的支持就是我更新的动力,非常感谢!