
分布式搜索引擎概念
1.搜索引擎是什么?
搜索引擎是一个检索服务,主要分全文检索和垂直检索,比如 solr/elasticsearch
2.elasticsearch
elasticsearch是一个分布式的索引库,我这里简单理解成一个nosql的数据库,它对外提供检索服务,使用的是http协议(之前也用transport协议,6.x开始已被废弃,现在用于集群内部通信),对内就是个nosql数据库。
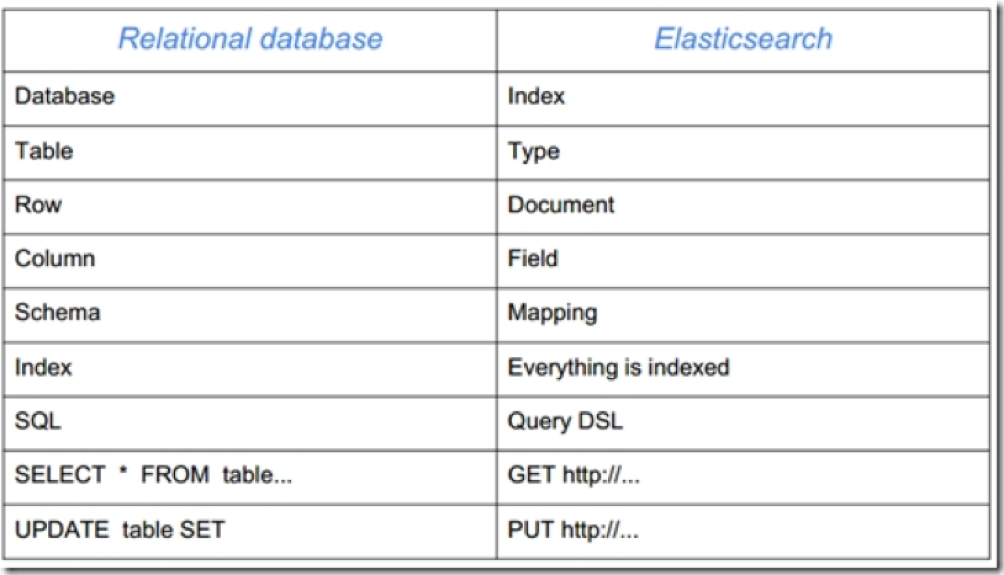
在ElasticSearch中我们会经常听到以下名词,现在我来将它和关系型数据库做一个对比:
3.分词
分词可以说是搜索引起的基石,如果一个搜索引擎没有好的分词器那么这个搜索引擎必然是失败的。
搜索是以词作为最小单元,依靠分词器进行构建,最后会生成一个倒排索引。
- 倒排索引:
倒排的意思就是我们把value对应成key,因为一个value是没有有办法得出确定的一篇文档的,可以得出很多。这就是倒排索引跟正向索引最大的不同点。 - 正向索引:
类似我们的HashMap。
4.TF-IDF
- TF:词频 一篇doc中包含了多少这个词,包含越多表明越相关。
- DF:文档频率 包含这个词的文档总数,比如 搜奶粉,你就去找
奶粉在多少篇文档中出现了。 - IDF = 1/DF:逆文档,DF取反 也就是 1/DF;如果包含该词的文档越少,也就是DF越小,IDF越大,则说明词对这篇文档重要性就越大。
- TFIDF: TF*IDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力。