
背景
最近项目上遇到一个改造主键生成策略的问题:需要将原Redis自增id改造成雪花算法。
一个好消息是项目用的ORM框架(Mybatis-Plus)自带雪花算法生成策略,只需在id字段上加上特定的注解。
而问题在于该策略生成id为19位数, 如:1582631966690799617,这样的id返给前端存在精度丢失问题。
当然,一个简单的办法就是将id转化为string类型,但是该业务流程长,涉及范围广,改动地方太多。
所以为了解决这样的问题,我起了改造雪花算法生成策略的心思,也将这次改造过程中的收获分享出来。
在此之前我先给大家介绍一下什么是雪花算法及原理
雪花算法
起源
雪花算法(snowflake)最早是twitter内部使用的分布式下唯一id生成算法
https://github.com/twitter-archive/snowflake
该算法具有以下特性
- 唯一性:高并发分布式系统中生成id唯一
- 高性能:每秒可生成百万个id
- 有序性:生成的id是有序递增的
原理
雪花算法生成的id由64个bit组成,其中41bit填充时间戳,10bit填充工作机器id,12bit作为自增序列号。
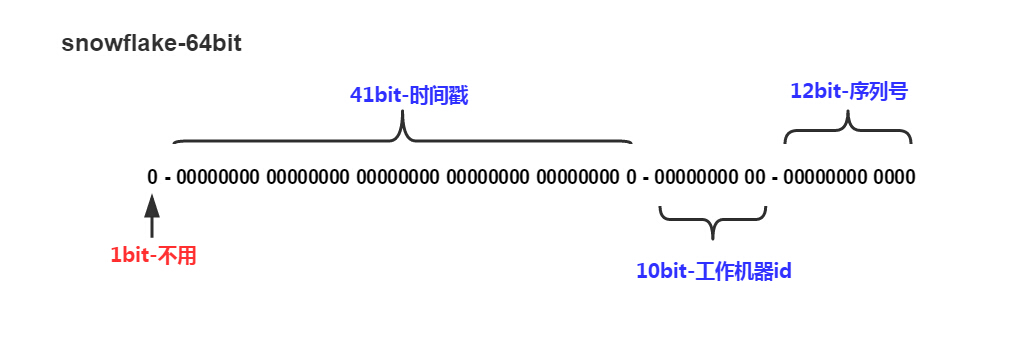
假设时间戳:1666168108422(ms), 转为二进制:11000001111101111010110111011010110000110
工作机器id: 1, 转为二进制:0000000001
序列号:1,转为二进制:000000000001
以上组成二进制为:11000001111101111010110111011010110000110-0000000001-000000000001
转为十进制:6988415561826833844,一个id号就这样生成了。
接下来分别介绍每部分的内容。
时间戳
时间戳一般通过当前时间-基准时间计算得出。
基准时间一般取最近时间(系统上线时间)。
因为当前时间是以1970年为基准时间算起的,而我们只需要从系统上线时算起就可以了。
为什么要这样做呢?我们可以来算一下该算法可以支持系统运行到多少年。
首先算出41bit的最大数值:11111111111111111111111111111111111111111(二进制) -> 2199023255551(十进制)
假设我们以1970年作为基准时间,那么当时间达到2199023255551时,时间戳部分就超出41bit了。
将2199023255551进行时间戳转换:2039-09-07 23:47:35
以1970年作为基准时间,该算法可运行至
2039-09-07 23:47:35
假设我们以最近时间2022-10-19 00:00:00作为基准时间。
将2022-10-19 00:00:00转为时间戳:1666108800000
那么系统可达到的最大时间为:1666108800000 + 2199023255551 = 3865132055551
3865132055551进行时间戳转换:2092-06-24 15:47:35
以2022年10月19日作为基准时间,该算法可运行至
2092-06-24 15:47:35
工作机器id
工作机器id部分可以用来保证生成id的唯一性:分布式系统中,每个节点的工作机器id不同,那么生成的id也一定不同。
该部分占用10bit, 意味着可以部署1024个节点。
工作机器id的设置可以由开发者手动设置,比如设置在JVM启动参数中,或者配置文件里,以保证工作机器id在每个节点的唯一性。
当然,如果节点太多对于配置来说也是灾难性的,此时可以考虑使用机器的mac地址或者ip做hash运算,以此作为工作机器id,但这就可能造成hash碰撞导致工作机器id重复(碰撞概率取决于hash算法),从而会有极小的概率生成id重复。
有时我们没有那么多的节点需要部署,那么就可以缩减该部分的bit位,用于增加时间戳部分bit位延长算法的使用时间,或者增加序列号部分增加每毫秒可生成的id树。
有时我们一个节点可能会部署多个实例,那么可以将10bit拆分,取5bit作为机器id,5bit作为进程id。
当然,你也可以取其中几个bit做业务标识。
由此可见,工作机器id部分是最容易自定义的部分
序列号
序列号部分用于在同一毫秒同一机器上生成不同的id号。
该部分占12bit,意味着同一毫秒同一机器上可生成4096个序列号,1秒即为4096000个(4百万)
和另外两个部分一样,该部分同样可以调整,如果单个实例的并发量确认达不到这么高,那么同样可以缩减该部分,将bit位让予其他部分使用。
实现
知道原理之后,接下来分析一下代码应当如何实现。
时间戳
时间戳部分有41bit, 值为当前时间戳 - 基准时间,转化为JAVA代码即为
long twepoch = 1666108800000L;
long time = System.currentTimeMillis() - twepoch;
这里在高并发多线程的场景下有个小小的优化点,可以使用定时任务线程池将System.currentTimeMillis()缓存起来,其他线程从缓存中获取。
public class SystemClock {
private final long period;
private final AtomicLong now;
private SystemClock(long period) {
this.period = period;
this.now = new AtomicLong(System.currentTimeMillis());
scheduleClockUpdating();
}
private void scheduleClockUpdating() {
ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(runnable -> {
Thread thread = new Thread(runnable, "System Clock");
thread.setDaemon(true);
return thread;
});
scheduler.scheduleAtFixedRate(() -> now.set(System.currentTimeMillis()), period, period, TimeUnit.MILLISECONDS);
}
private long currentTimeMillis() {
return now.get();
}
}
这里直接给出原因:
- 单线程情况下,直接调用
System.currentTimeMillis()更快 - 高并发多线程情况下,使用缓存获取时间戳更快
具体测试过程见文末参考
工作机器id
工作机器id可以在构造方法中传入,也可以取mac地址hash,方法如下
long id = 0L;
try {
NetworkInterface network = NetworkInterface.getByInetAddress(getLocalAddress());
if (null == network) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
if (null != mac) {
id = ((0x000000FF & (long) mac[mac.length - 2]) | (0x0000FF00 & (((long) mac[mac.length - 1]) << 8))) >> 6;
id = id & 1023;
}
}
} catch (Exception e) {
log.warn(" getWorkId: " + e.getMessage());
}
return id;
序列号
序列号在每一毫秒从0开始,如果同一毫秒生成多个id,则进行自增即可。
这里有两个要注意的点:
1、当序列号达到最大值时的问题
比如序列号占12bit位,最大值为4095,当序列号在同一毫秒自增到4095时,再加1则会超出bit位,此时需要将序列号重置为0,但是重置为0就会出现同一毫秒有两个序列号为0的id,所以重置为0的同时还需要等待至下一毫秒。
2、数据倾斜问题
如果序列号从0自增,那么对于大部分同一毫秒内只会有一个请求的系统,生成的id号序列号大部分为0(偶数),此时如果以id进行分表,就会造成数据的严重倾斜。该问题可以用过序列号从(0,1)随机开始自增。
3、时间回拨问题
时间回拨时可通过等待,或者使用过去时间生成id解决。
private long getSequence(){
long timestamp = timeGen();
// 闰秒
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
// 休眠双倍差值后重新获取,再次校验
wait(offset << 1);
timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
} else {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));
}
}
if (lastTimestamp == timestamp) {
// 相同毫秒内,序列号自增
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 同一毫秒的序列数已经达到最大
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 不同毫秒内,序列号置为 0|1 随机数
sequence = ThreadLocalRandom.current().nextLong(0, 2);
}
return sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
整体代码
public class MySequence {
private static final Logger log = LoggerFactory.getLogger(MySequence.class);
/**
* 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
*/
private final long twepoch = 1666108800000L;
/**
* 10位的机器id
*/
private final long workerIdBits = 10L;
/**
* 12位的序列号 每毫秒内产生的id数: 2的12次方个
*/
private final long sequenceBits = 12L;
/**
* 1023
*/
protected final long maxWorkerId = ~(-1L << workerIdBits);
/**
* 机器id左移动位
*/
private final long workerIdShift = sequenceBits;
/**
* 时间戳左移动位
*/
private final long timestampLeftShift = sequenceBits + workerIdBits;
/**
* 4095
*/
private final long sequenceMask = ~(-1L << sequenceBits);
/**
* 所属机器id
*/
private final long workerId;
/**
* 并发控制序列
*/
private long sequence = 0L;
/**
* 上次生产 ID 时间戳
*/
private long lastTimestamp = -1L;
public MySequence() {
this.workerId = getWorkerId();
}
/**
* 有参构造器
*
* @param workerId 工作机器 ID
*/
public MySequence(long workerId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("Worker Id can't be greater than %d or less than 0", maxWorkerId));
}
this.workerId = workerId;
}
/**
* 基于网卡MAC地址计算余数作为机器id
*/
protected long getWorkerId() {
long id = 0L;
try {
NetworkInterface network = NetworkInterface.getByInetAddress(InetAddress.getLocalHost());
if (null == network) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
if (null != mac) {
id = ((0x000000FF & (long) mac[mac.length - 2]) | (0x0000FF00 & (((long) mac[mac.length - 1]) << 8))) >> 6;
id = id % (maxWorkerId + 1);
}
}
} catch (Exception e) {
log.warn("getWorkerId: " + e.getMessage());
}
return id;
}
/**
* 获取下一个 ID
*
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 闰秒
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
// 休眠双倍差值后重新获取,再次校验
wait(offset << 1);
timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
} else {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));
}
}
if (lastTimestamp == timestamp) {
// 相同毫秒内,序列号自增
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 同一毫秒的序列数已经达到最大
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 不同毫秒内,序列号置为 1 - 3 随机数
sequence = ThreadLocalRandom.current().nextLong(1, 3);
}
lastTimestamp = timestamp;
// 时间戳部分 | 机器标识部分 | 序列号部分
return ((timestamp - twepoch) << timestampLeftShift)
| (workerId << workerIdShift)
| sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
}
改造
要解决JS精度丢失的问题,就要清楚原因是什么。
这是因为JS的number类型最大精度为2^53,即9007199254740992
转为二进制:100000000000000000000000000000000000000000000000000000 (54位)
那么我们只要让生成的id不超过9007199254740991即可
转为二进制:11111111111111111111111111111111111111111111111111111(53位)
可对此53位做以下分配
(1)时间戳(41位)-工作机器id(6位)-序列号(6位):最大支持64个workerId, 每毫秒生成64个序列号
(2)时间戳(39位)-工作机器id(4位)-序列号(10位):最大支持16个workerId, 每毫秒生成1024个序列号
此两种情况分别为两个极端,下面分别计算此两种情况的使用时长
第一种
41位时间戳的最大值为:2199023255551
取当前时间戳:1666108800000
计算:1666108800000 + 2199023255551 = 3865132055551(2092-06-24 15:47:35)
系统运行至2092年达到最大值
第二种
39位时间戳的最大值为:549755813887
取当前时间戳:1666108800000
计算:1666108800000 + 549755813887 = 2215864613887(2040-03-20 21:56:53)
系统运行至2040年达到最大值
使用
于是结合雪花算法原理,我对需要改造的项目从并发量(序列号)和实例数(工作机器id)方面做了调研。
从调研结果进行了bit位分配。
并且基于现有的id最大值,计算了基准数,让修改后的id生成策略必然大于以前的id。
最后该策略已上线运行,达到了预期结果。
小结
雪花算法的特点:唯一性,高性能,有序性。
雪花算法的三个部分:时间戳、工作机器id、序列号。
JS最大精度为2^53, 生成的id不超过该数即可。
使用时可根据实际业务情况对三个部分的bit位进行调整。
参考:
分布式高效ID生产黑科技: https://gitee.com/yu120/sequence
System.currentTimeMillis的性能真有如此不堪吗?: https://juejin.cn/post/6887743425437925383