
前置知识:位图算法
在讲位图算法时我们说到位图算法的缺陷是不能处理数据重复问题,也就是数据hash值产生冲突时,只知道这里有值,但是不知道有几个,是谁的。
最经典的问题就像这个:
假设有一个10亿的email黑名单,怎么通过这个黑名单过滤邮件?
当然,你可能会说,是不是布隆过滤器?
我当然也会回答你:是的!
但是,抛开这篇文章不谈,你有什么思考吗?
解决方式
-
使用MySQL进行存储
这当然是最简单也最直接的办法,但我们知道MySQL的表空间是有上限的,并且在《阿里巴巴JAVA开发规范》中也明确表示:每张表的记录最好不要超过500万。当然,我们也可以进行分表处理,假设每张表存500万,我们需要分出10亿/500万 = 200张表,这显然是不可取的,别说项目经理会把你骂成🐶,你可能也会问自己,这什么JB玩意?
-
BitMap
还记得我们讲位图算法时的问题吗?
假设有2亿个数,范围在0~3亿,给出一个数,判断2亿个数中是否存在该数?
我就问你像不像?
那么我们现在假设使用BitMap解决该问题
初始化操作:定义一个10亿的bit数组,将email进行hash运算,把对应的bit位置为1
判断某个邮箱是否在黑名单内:对该邮箱进行hash,将hash值与bit数组比较,判断对应的bit位是否为1,是则表示这个邮箱是黑名单里的。
时间复杂度:O(1)
空间复杂度:10亿 / 8 / 1024 / 1024 = 119M
好像解决了哈,但是但是,假设我们黑名单上有个email: lzj960515@163.com, 它的hash值为1,这时,有一个不在黑名单的email:lzj960515@gmail.com, 它的hash值也为1, 程序就会出现lzj960515@gmail.com是黑名单上的email的误判。如果这是你的邮箱系统,那你就可能隔三差五收到用户投诉:怎么把我的邮箱屏蔽了?!
那么我们该如何解决这个问题呢?
布隆过滤器
概念
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
结构
它的结构和我们讲的BitMap非常类似。它是由一个很长的bit数组以及k个hash函数组成。
原理
当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:**如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。**这就是布隆过滤器的基本思想。
以上都是抄的维基百科
不知道你有没有注意到原理中的一句话:如果都是1,则被检元素很可能在,为什么是可能在呢?
假设我们有以下16bit长度的数组

我们有两个email: lzj960515@163.com 834135043@qq.com
有两个hash函数: hash1 hash2,对他们分别计算hash值
- lzj960515@163.com hash1 -> 2 hash2 -> 6
- 834135043@qq.com hash1 -> 4 hash2 -> 9
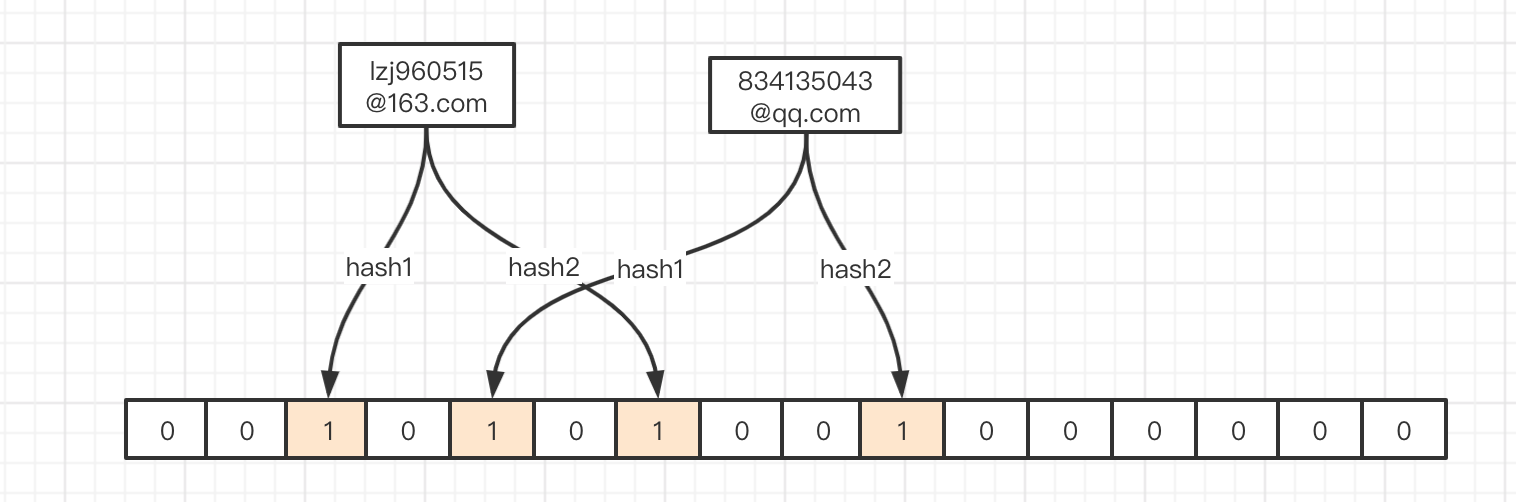
此时判断834135043@qq.com是否存在很简单,只需用hash1和hash2分别hash后判断数组对应的位置是否为1即可。
我们现在,增加一个email: lzj960515@gmail.com
hash结果: hash1 -> 6 hash2 -> 11
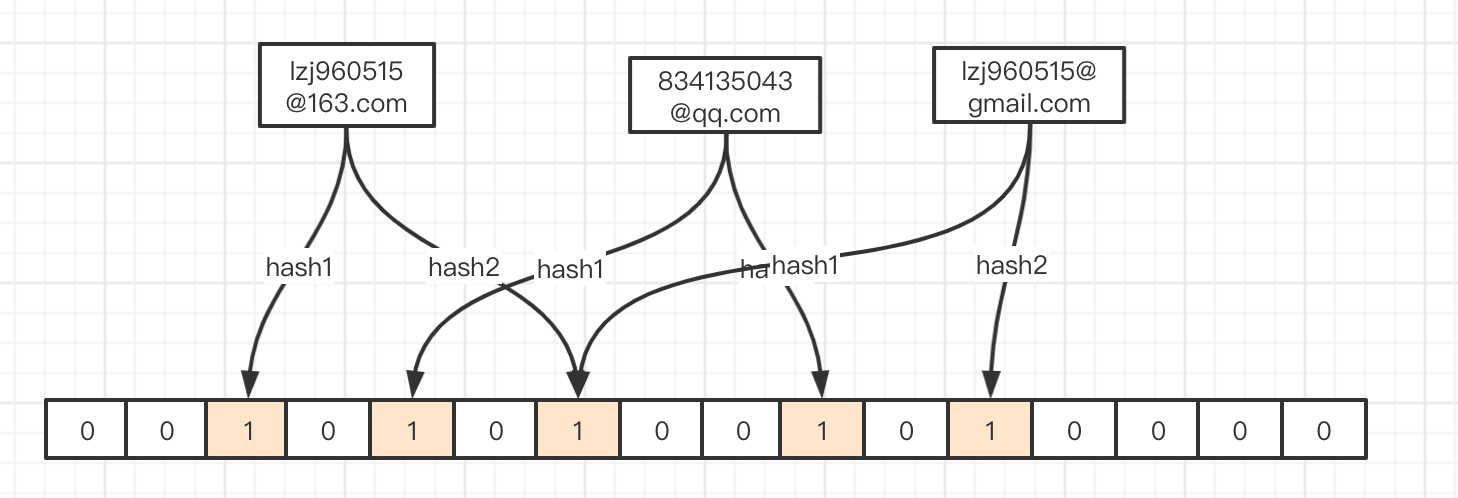
我们发现,虽然 lzj960515@gmail.com 的hash1值和lzlj960515@163.com的hash2值冲突了,但是并不影响我们的判断。
现在,我需要判断lzj960515@sina.com这个邮箱是否存在
它的hash结果:hash1 -> 1 hash2 -> 4
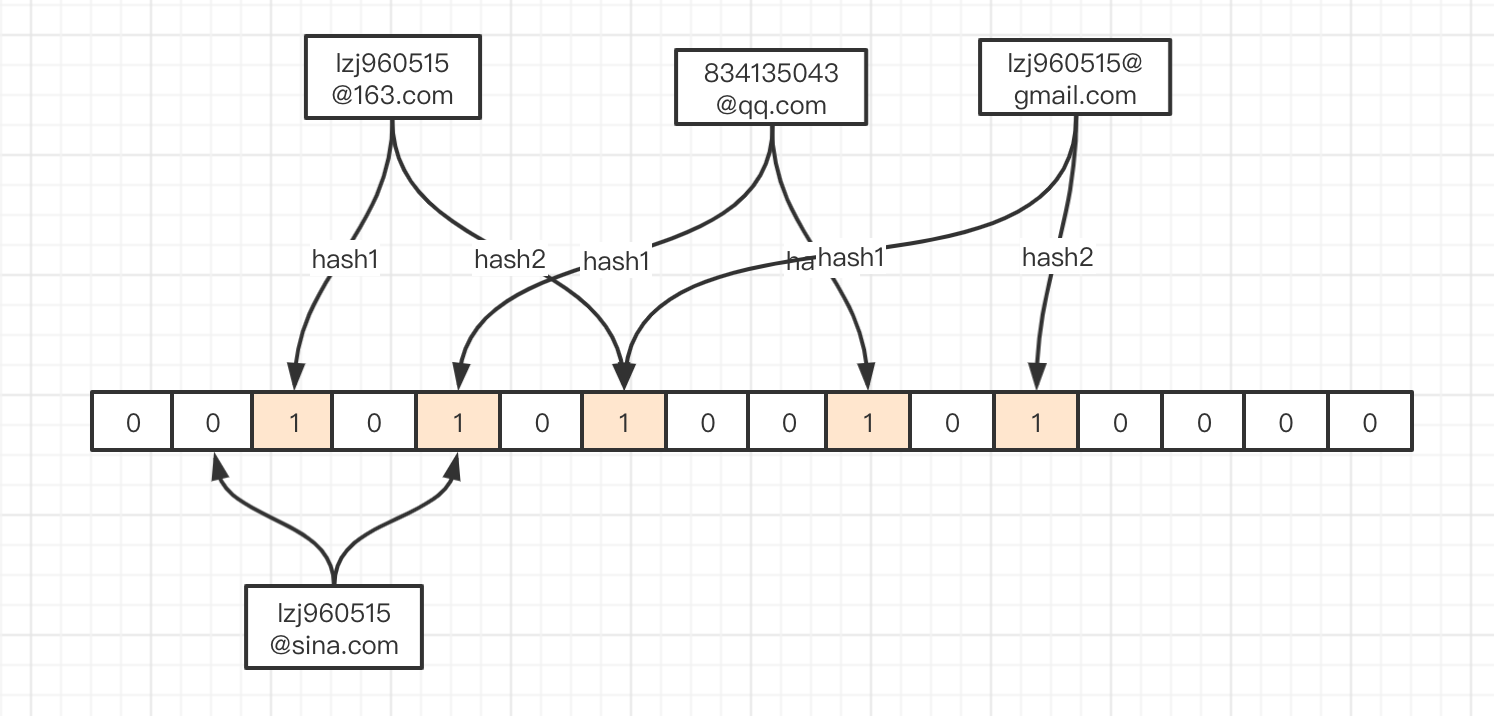
可以看到,lzj960515@sina.com对应的hash1位为0,于是我们得出判断:该邮箱不在黑名单中。
它的hash结果:hash1 -> 2 hash2 -> 9
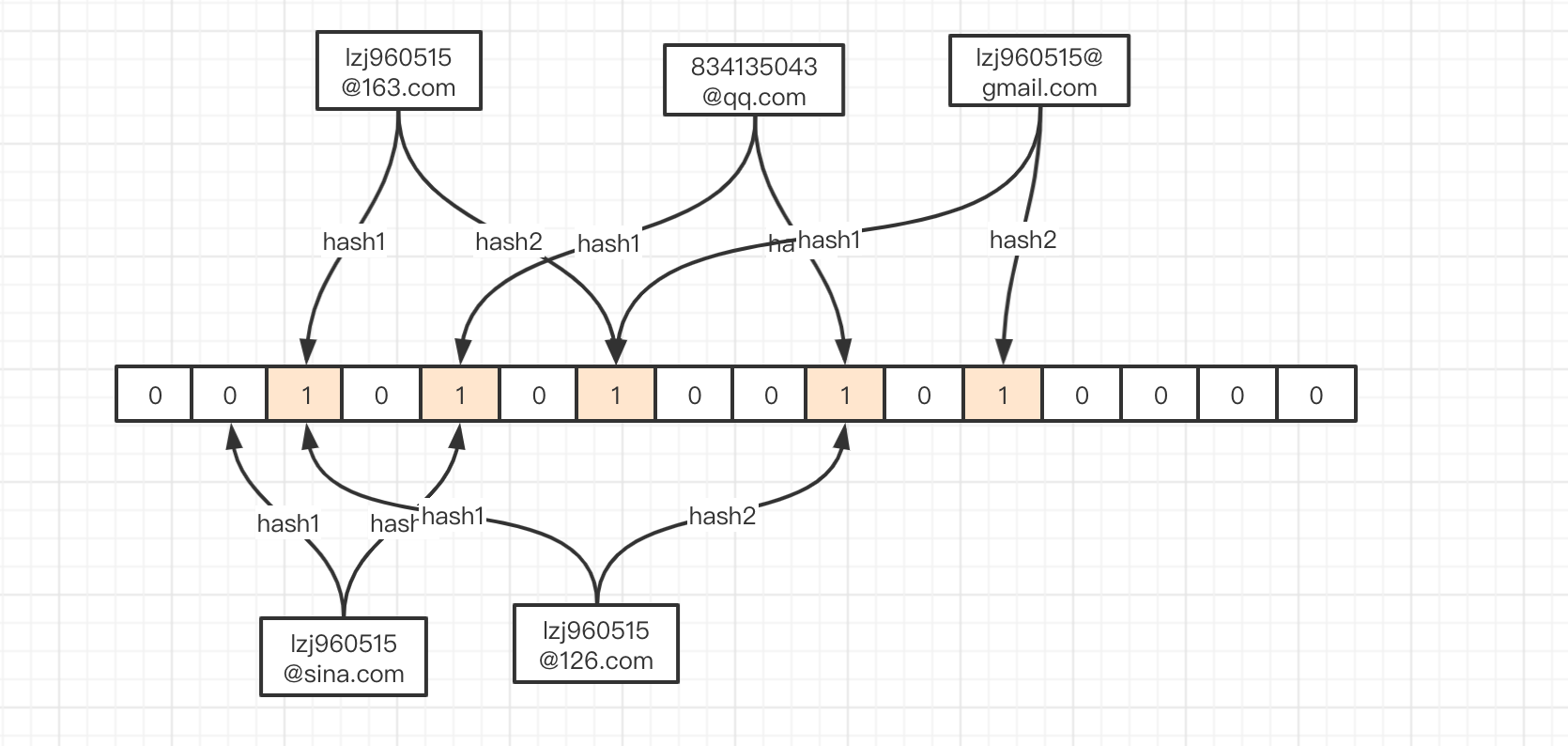
发现问题了吗?lzj960515@126.com对应的两个hash位都为1,但是,它其实并不存在黑名单中。
那么,该如何解决这个问题?
这个问题的根本原因还是在于hash碰撞,如果我们能够减少hash碰撞也就能减少该问题的产生。其实就是降低误差率。
hash碰撞只能降低,不能完全解决,可以说有hash的地方就会有hash碰撞
降低误差率的方式:
-
增加数组长度
这一点我想应该是毫无疑问的,当伴随的数组的长度增加,我的hash值落点也自然更加散列,就比如有两个hash值17 、33,当数组长度为16时,他们的落点分别是 17%16=1,33%16=1,此时发生hash碰撞,当数组长度为32时,17%32=17, 33%16=1,hash碰撞消失了。
-
增加hash函数的数量
在描述上述问题时,我们使用了两个hash函数,如果我们再增加一个hash函数,那么多个hash碰撞的概率就会减小,两次hash你都碰撞了,三次hash总不碰吧,三次还碰,四次呢?当然,我们也不可能无休止的增加下去,这不仅会降低我们的效率,而且一个16bit长度的数组,你搞16个hash函数,玩个蛋!
那么,我们应当如何在这两者之间权衡,加数组长度 or 加hash函数 (增加空间复杂度or增加时间复杂度)
以下,是大佬们推出的数学公式:
m为开的长度, n为元素个数, k为哈希函数个数为, p为误判率
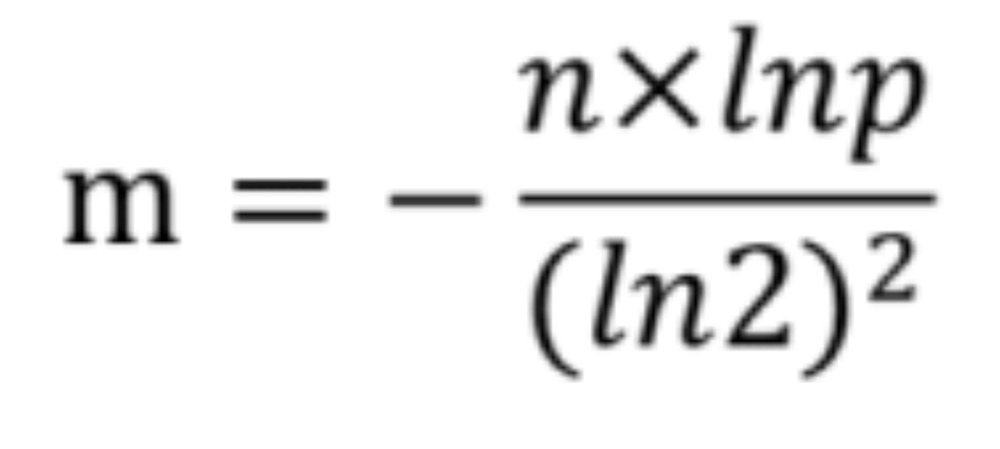
开的空间
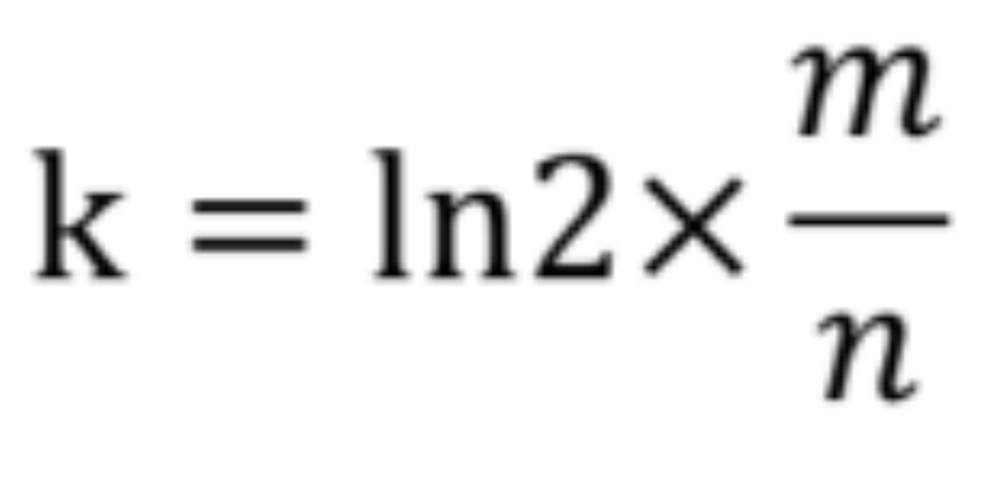
哈希函数的个数
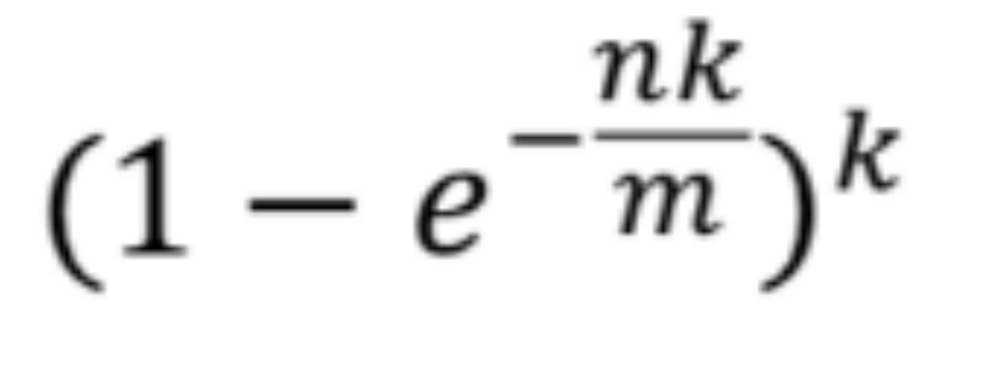
真实误差率
上代码
讲到这里,相信大家已经明白什么是布隆过滤器了,现在,我们就来实现一下吧
public class BloomFilter {
int size;
// 这里借用java自带的BitSet
BitSet bits;
public BloomFilter(int size) {
this.size = size;
bits = new BitSet(size);
}
public void add(String key) { //O(1)
int hash1 = hash_1(key);
int hash2 = hash_2(key);
int hash3 = hash_3(key);
bits.set(hash1, true);
bits.set(hash2, true);
bits.set(hash3, true);
}
public boolean find(String key) {
int hash1 = hash_1(key);
if (!bits.get(hash1))
return false;
int hash2 = hash_2(key);
if (!bits.get(hash2))
return false;
int hash3 = hash_3(key);
if (!bits.get(hash3))
return false;
return true;
}
public int hash_1(String key) {
int hash = 0;
int i;
for (i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return Math.abs(hash) % size;
}
public int hash_2(String key) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++) {
hash = (hash ^ key.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash) % size;
}
public int hash_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash) % size;
}
public static void main(String[] args) {
// O(1000000000)
//8bit= 1byte
BloomFilter bloomFilter = new BloomFilter(Integer.MAX_VALUE); //21亿
System.out.println(bloomFilter.hash_1("1"));
System.out.println(bloomFilter.hash_2("1"));
System.out.println(bloomFilter.hash_3("1"));
bloomFilter.add("1111");
bloomFilter.add("1123");
bloomFilter.add("11323");
System.out.println(bloomFilter.find("1"));
System.out.println(bloomFilter.find("1123"));
}
}
有没有发现实现超级简单,当然,我这里写死了3种hash函数。
细心的你可能发现了,这里没有删除功能,那么布隆过滤器应当如何删除呢?这里可以很直接的告诉大家:布隆过滤器不能删除,至于为什么就留给大家自己想啦
其实谷歌的guava工具包中给我们提供了一个比较完美的布隆过滤器
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0-jre</version>
</dependency>
测试
package cn.zijiancode.pig.util;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author Zijian Liao
* @since 1.0.0
*/
public class BloomFilterTest {
public static void main(String[] args) {
//我们要插入的数据也就是n
int datasize = 100000000;
//0.1% 误判率
double fpp = 0.001;
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), datasize, fpp);
long start = System.currentTimeMillis();
for(int i = 0 ; i < datasize ; i ++) {
bloomFilter.put(i);
}
System.out.println((System.currentTimeMillis() - start) + ":ms");
// 测试误判率
int count = 0;
for(int i = 200000000 ; i < 300000000 ; i++){
if(bloomFilter.mightContain(i)){
count++;
}
}
System.out.println("误判的个数:" + count);
}
}
结果:
126902:ms
误判的个数:99777
99777/100000000 = 0.00099777 -> 0.1%
小结
本篇通过一个小问题介绍了布隆过滤器
优点:
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数O(k)。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点:
误算率。
应用场景:
- 爬虫过滤
- 缓存击穿
- 垃圾邮件过滤
- 秒杀系统中重复购买
- ...