
概述
explain是MySQL中的一个关键字,可以用于模拟优化器执行SQL语句,分析你的SQL的性能瓶颈。
使用时只需将该关键字加在sql头部,如
explain select * from employees where name = 'zhangsan'
案例
explain返回的结果有许多字段,我们又当如何理解呢?
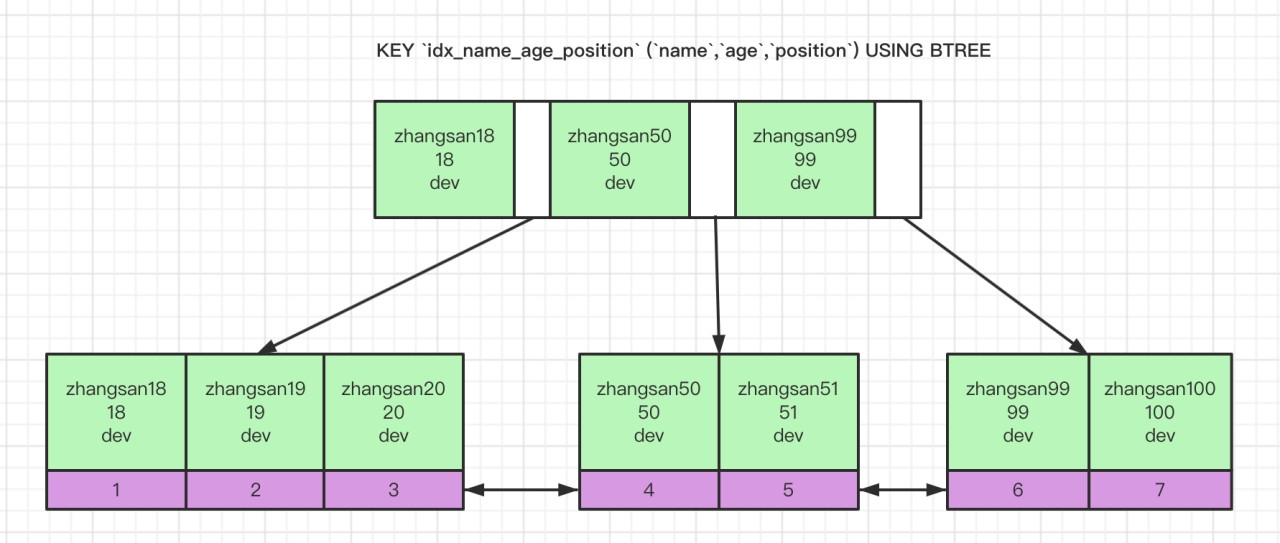
以下有张员工记录表,联合索引:name_age_position
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
执行sql
explain select * from employees where name = 'zhangsan'
explain结果

现在,可以简单解读以下其中几个列
1、select_type: 查询类型,SIMPLE:简单查询
2、table: 查询的表
3、possible_keys: 执行该sql可能会用的索引,注意是可能,该列意义不大。
4、key: 执行该sql实际使用的索引,有没有走索引主要看该列
5、key_len: 索引所用的字节数(长度),通过该列可以判断使用了联合索引的哪几个字段。
没错,索引是有长度的,索引的长度等于该索引包含字段长度之和,具体计算规则如下:
- 字符串
- char(n):n字节长度
- varchar(n):如果是utf-8,则长度 3n + 2 字节,加的2字节用来存储字符串长度
- 数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
- 时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
- 如果字段允许为 NULL,需要1字节记录是否为 NULL
案例表中的字段name类型为varchar(24),长度即为:3*24+2=74,符合explain中的结果。
如果我们使用该sql语句
explain select * from employees where name = 'zhangsan' and age = 18 and position = 'dev';

name类型为varchar(24),长度:3*24+2=74
age类型为int, 长度:4
position类型为varchar(20),长度:3*20+2=62
74+4+62=140
复杂查询
接下来,我们看一个稍显复杂的例子
explain
select * from employees t1
join (select id from employees order by name limit 10000, 10) t2
ON t1.id = t2.id;
该语句含义为:查询以name字段排序的第10000~10010行记录
至于为什么不直接
select * from employees order bynamelimit 10000, 10会在后续索引优化中解释

1、id列:该列并非单纯指返回结果的id,因为你可能也注意到了,第一行和第二行id都为1
id列的具体含义为:id列的编号是select的序列号,有几个select就有几个id,并且id的顺序是按select出现的顺序增长的。id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
2、select_type:
- primary:复杂查询中最外层的select
- derived:包含在from子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
3、table列:deriven2表示:当from子句中有子查询时,table列是<derivenN>格式,表示当前查询依赖id=N的查询,于是先执行id=N的查询。
意思就是第一行依赖于第三行id=2的查询
4、type列
-
ALL:即全表扫描,扫描你的聚簇索引的所有叶子节点。
-
eq_ref:
primary key或unique key索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。 -
index:扫描全索引,一般是扫描某个二级索引
5、ref列: 这一列显示了在key列记录的索引中,表查找值所用到的列或常量
6、row列:mysql估计要读取并检测的行数
6、Extra列:
-
Using index:使用覆盖索引
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引
结合以上列的解释,该sql语句的执行计划大概可以这样阐述:
1、先使用联合索引执行select id from employees order by name limit 10000, 10语句,将查询结果id放入临时表中。
2、全表扫描该临时表
3、使用id关联查询select * from employees t1
关于explain的用法大概就是这些,更为详细的理论内容可查看Explain详解和索引最佳实践和官网文档
trace工具
为什么有时候explain的结果和我们的期望不同?
这是因为MySQL优化器会进行成本计算,MySQL觉得不走索引还会快一些。
比如该sql
explain select * from employees3 where name > 'bb';

可以看到在执行计划中不会使用任何索引
关于执行成本,我们可以通过trace工具查看
-- 开启trace
set session optimizer_trace="enabled=on",end_markers_in_json=on;
-- 执行sql
explain select * from employees3 where name > 'bb';
-- 查看结果
SELECT * FROM information_schema.OPTIMIZER_TRACE;
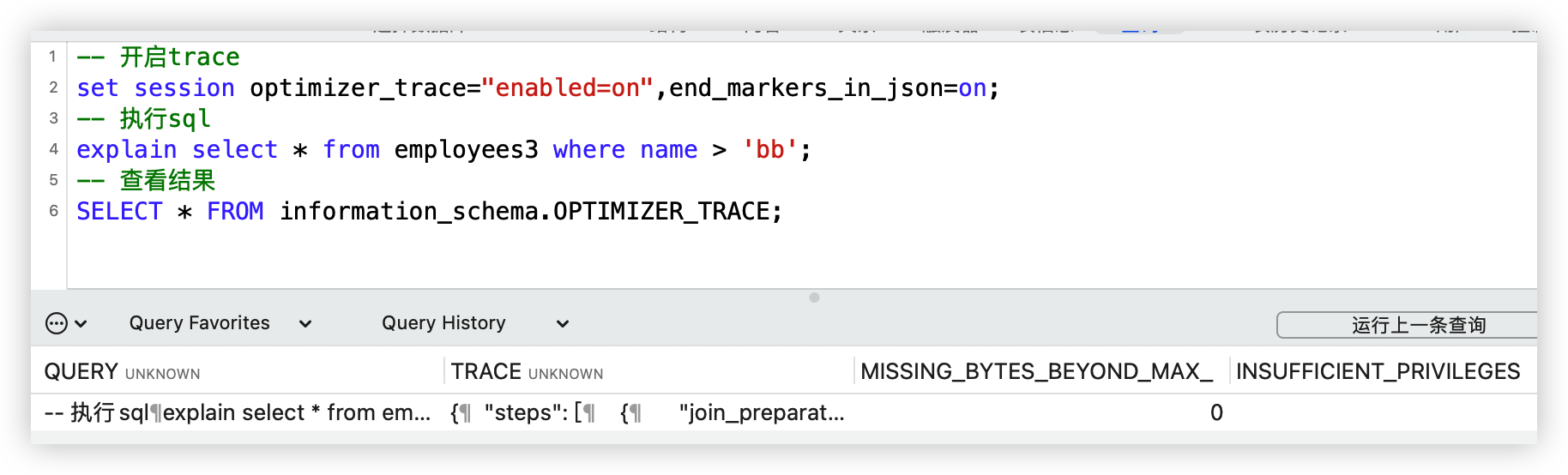
大致内容和解释如下
{
"steps": [
{
"join_preparation": { -- 第一阶段:SQL准备阶段,格式化sql
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'LiLei')"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { -- 第二阶段:SQL优化阶段
"select#": 1,
"steps": [
{
"condition_processing": { -- 条件处理
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'LiLei')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`employees`.`name` > 'LiLei')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`employees`.`name` > 'LiLei')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`employees`.`name` > 'LiLei')"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": {
} /* substitute_generated_columns */
},
{
"table_dependencies": [ -- 表依赖详情
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ -- 预估表的访问成本
{
"table": "`employees`",
"range_analysis": {
"table_scan": { -- 全部扫描情况
"rows": 100127, -- 扫描行数
"cost": 20380 -- 查询成本
} /* table_scan */,
"potential_range_indexes": [ -- 查询可能使用的索引
{
"index": "PRIMARY", -- 主键索引
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_name_age_position", -- 辅助索引
"usable": true,
"key_parts": [
"name",
"age",
"position",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"analyzing_range_alternatives": { -- 分析各个索引使用成本
"range_scan_alternatives": [
{
"index": "idx_name_age_position",
"ranges": [
"LiLei < name" -- 索引使用范围
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false, -- 使用该索引获取的记录是否按照主键排序
"using_mrr": false,
"index_only": false, -- 是否使用覆盖索引
"rows": 50063, -- 索引扫描行数
"cost": 60077, -- 索引查询成本
"chosen": false, -- 是否选择
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`employees`",
"best_access_path": { -- 最优访问路径
"considered_access_paths": [ -- 最终选择的访问路径
{
"rows_to_scan": 100127,
"access_type": "scan", -- 全表扫描
"resulting_rows": 100127,
"cost": 20378,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 100127,
"cost_for_plan": 20378,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`employees`.`name` > 'LiLei')",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`employees`",
"attached": "(`employees`.`name` > 'LiLei')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"refine_plan": [
{
"table": "`employees`"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": {
"select#": 1,
"steps": [
] /* steps */
} /* join_execution */
}
] /* steps */
}