
前言
索引优化这四个字说实话我认为其实挺难理解的。看到这四个字我脑门上是:????
索引还要优化吗?调优SQL一般来说不就是看它有没有走索引,没走索引给它加上索引就好了吗?
嗯,所以你是怎么给它加索引的?
看SQL应该怎么走索引撒!
那SQL是怎么走索引的呢?又是怎么判断这条SQL会不会走索引呢?
我:…, 咱今天就来分析分析!
要是你还不了解MySQL底层的数据结构,建议你先看看MySQL数据结构
最左前缀法则
我们一般要优化的都是复杂SQL,而复杂SQL一般走的都是联合索引,说到联合索引的匹配规则,就逃不开这个:最左前缀法则
什么是最左前缀法则?
最左前缀法则即为:索引的匹配从最左边的字段开始,匹配成功才能往右继续匹配下一个字段。
不理解?没关系,我们先来看看这个联合索引:name_age_position
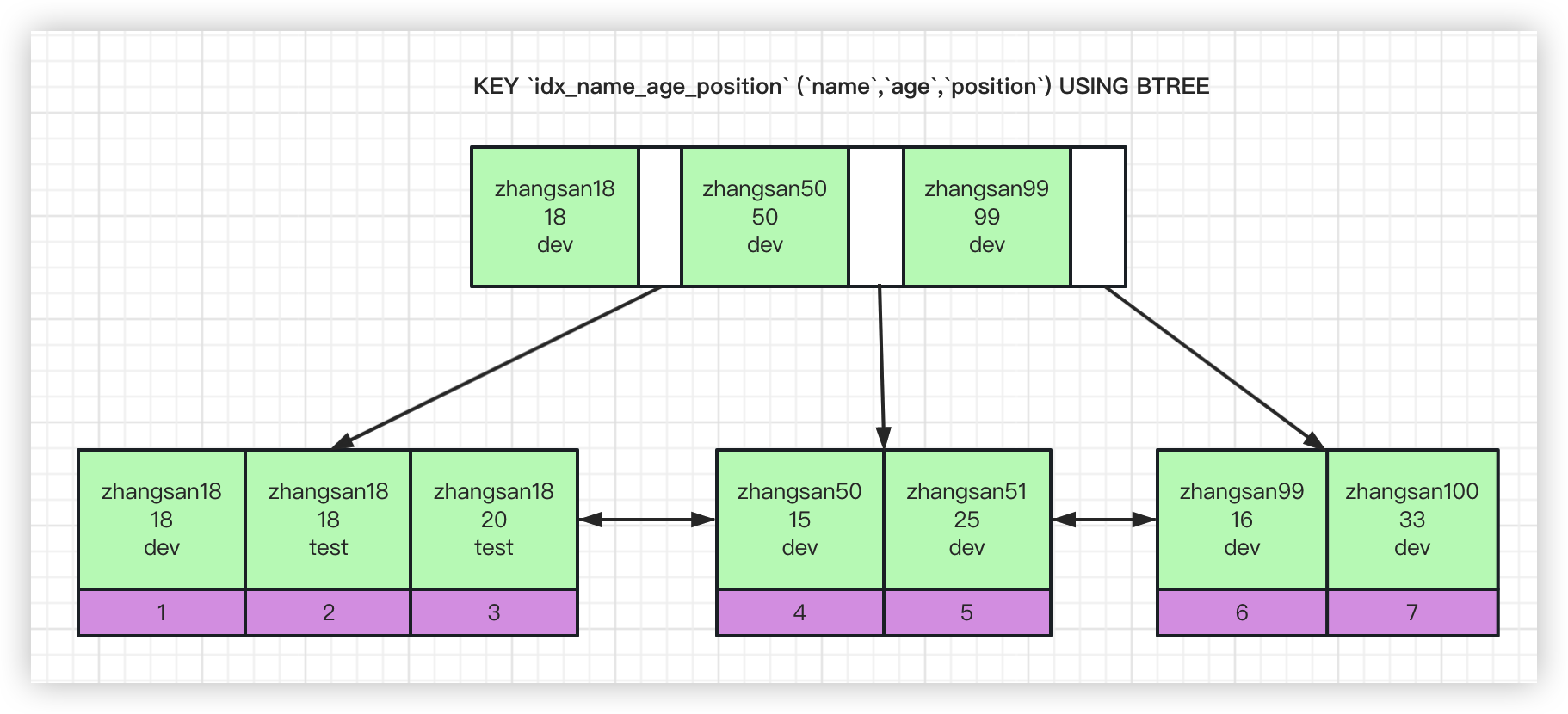
联合索引是以三个字段name,age,position组成,并且创建该索引时字段顺序为name、age、positon。
那么该索引就会以这样的方式排序(索引就是排好序的高效的数据结构)
- name字段从小到大排序
- name字段的值相同时,age字段从小到大排序
- age字段的值相同时,postion字段从小到大排序
如上图所示,从zhangsan18到zhangsan100是顺序的,而name都为zhangsan18的三个结点中,age又是从小到大排序,age相同时position也是从小到大排序。
请你一定要把这个数据结构牢记于心,忘了就看看
现在通过这个联合索引再来解析一下最左前缀法则:在索引匹配时,必须先能够匹配name字段(最左边的),才能继续匹配age字段(下一个), age字段匹配成功了才能匹配position字段。
为什么?
因为联合索引中的最左边字段是有序的,而第二个字段是在第一个字段相同的情况下有序,第三个字段是在第二个字段相同的情况下有序。
如果你想要用age字段直接在联合索引中查找数据,对不起,找不到,因为age字段中联合索引中是无序的。
你把第一行name字段遮掉看看age字段的情况:18,18,20,15,25,16,33。无序的对吧。
还是有点迷惑?没关系,我们再来通过案例分析分析。
什么是走索引?就是看索引会不会起到作用,能够起到作用就叫走了索引,没有起到作用就叫没走索引。
案例分析
表结构:
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时\r\n间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
sql1
explain select * from employees where name > 'zhangsan18'
name字段是联合索引最左边的字段,所以会走索引

sql2
explain select * from employees where age = 18
age字段并非联合索引最左边的字段,在索引中无序,故不走索引,全表扫描

sql3
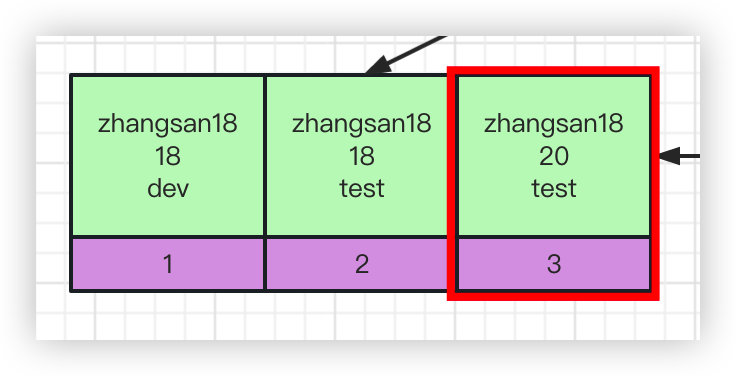
explain select * from employees where name = 'zhangsan18' and age = 20;
name字段和age字段都会走索引,因为在name字段相同时,age字段是有序的, 所以此时age也可以走索引。

以上图为例,当定位到zhangsan18时,可以直接定位到age=20这条数据,不需要从age=18的地方遍历寻找,所以索引对age字段也起到作用了。
你现在明白什么是最左前缀法则了吧,还不明白就私信我吧[叹气.jpg]。
SQL案例
现在,我们再来通过一些sql继续深挖这最左前缀法则。
sql4
explain select * from employees where age = 20 and name = 'zhangsan18';
和sql3相同,name和age都会走索引,最左前缀和你sql语句的位置无关,mysql在执行时会自动调整位置,也就是改成name = 'zhangsan18' and age = 20
sql5
explain select * from employees where name > 'zhangsan18' and age = 20;
只有name字段会走索引,age不会走索引,因为此时mysql的查询逻辑是定位到name=zhangsan18最右边的一条数据,然后通过叶子结点的指针向右扫描遍历,索引对age字段未起到作用。如图
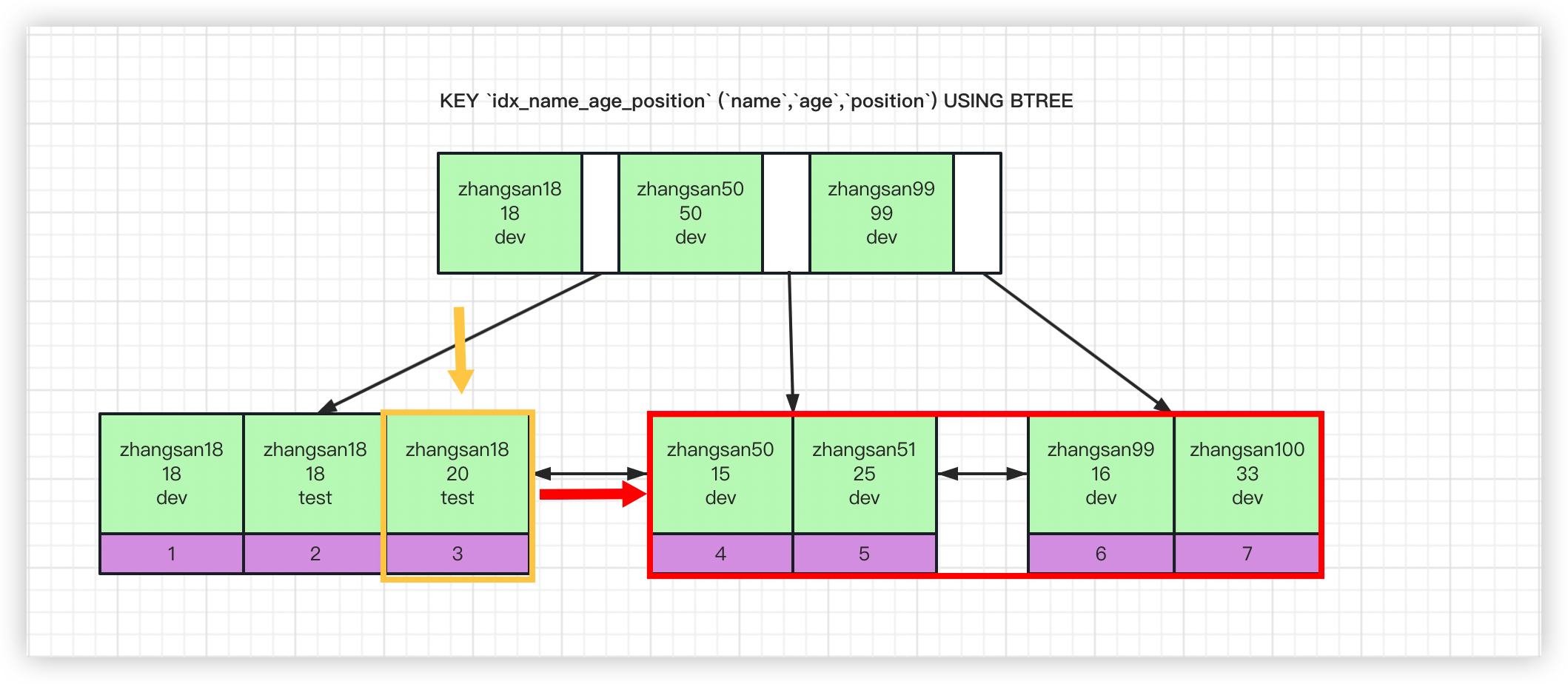
explain结果:

sql6
explain select * from employees where name >= 'zhangsan18' and age = 20;
和sql5差不多,唯一的区别就是name是大于等于。此时name和age都会走索引。

现在,我估计你一定晕了,网上不是说范围查找会导致索引失效吗?怎么还走了age字段。
这样,我把sql这样写:
explain select * from employees where (name = 'zhangsan18' and age = 20) or (name > 'zhangsan18' and age = 20);
name = 'zhangsan18' and age = 20部分:name和age都会走索引,这个没问题吧?
name > 'zhangsan18' and age = 20部分:name走索引,age不走索引,这个也我没问题吧?
合起来就是name和age都会走索引,因为name = 'zhangsan18' and age = 20时age要走索引。
还是迷惑?那梳理下流程。
mysql执行时先定位到name=zhangsan18, 然后由于后面还有个age=20条件,所以会直接定位到这里
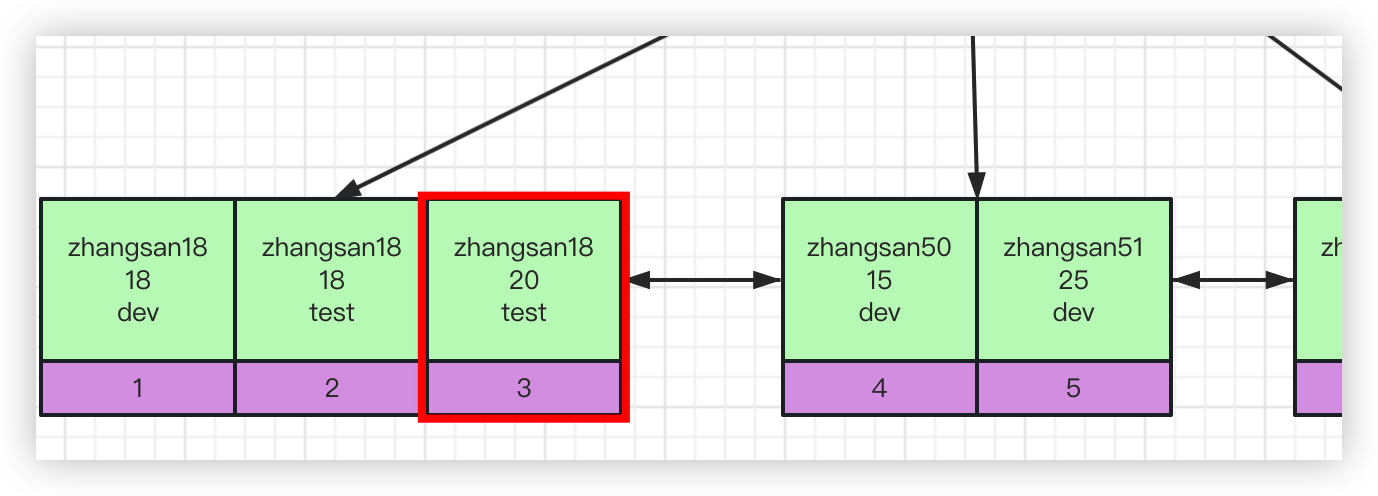
然后再往右扫描name>zhangsan18的记录, 你告诉我这个过程有没有用上age字段的索引?用上了吧,所有age字段也会走索引,也仅仅是这个时候会走索引,后面name>zhangsan18的还是不走索引。
sql7
explain select * from employees where name like 'zhangsan18%' and age = 10
name和age都会走索引,和sql6一样理解就好。
sql8
explain select * from employees where name between 'zhangsan18' and 'zhangsan50' and age = 10
name和age都会走索引
到这里,你对最左前缀法则应该会有个深刻的认识了,更多的想法,就由你自己去探索啦
索引下推
MySQL在5.6之后加了一个优化:索引下推,可以在索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效的减少回表次数
拿这条sql举例:
explain select * from employees where name > 'zhangsan18' and age = 20;
这条sqlname字段走索引,age不走索引,在没有索引下推时,查询逻辑是这样的:
1、存储引擎通过联合索引找到name > 'zhangsan18'的记录
2、然后使用联合索引存储的主键进行回表操作,查询出所有数据
3、将数据返回给Server层
4、Server层判断这条记录的age是否为20, 是则返回给客户端,否则丢弃
这里就有个优化点,在第一步用联合索引找到name > 'zhangsan18'的记录时,能不能直接判断age是否为20?如果是再进行后面的步骤。
哎,你觉得能不能?
能!age字段本来就在联合索引里面,直接判断就完事了~
所以,这就是索引下推。简单吧~