
这篇文章继续讨论剩下的内容,同样,请一定要先看MySQL索引优化一
分页查询
在平常,我们写的分页查询sql一般是这样
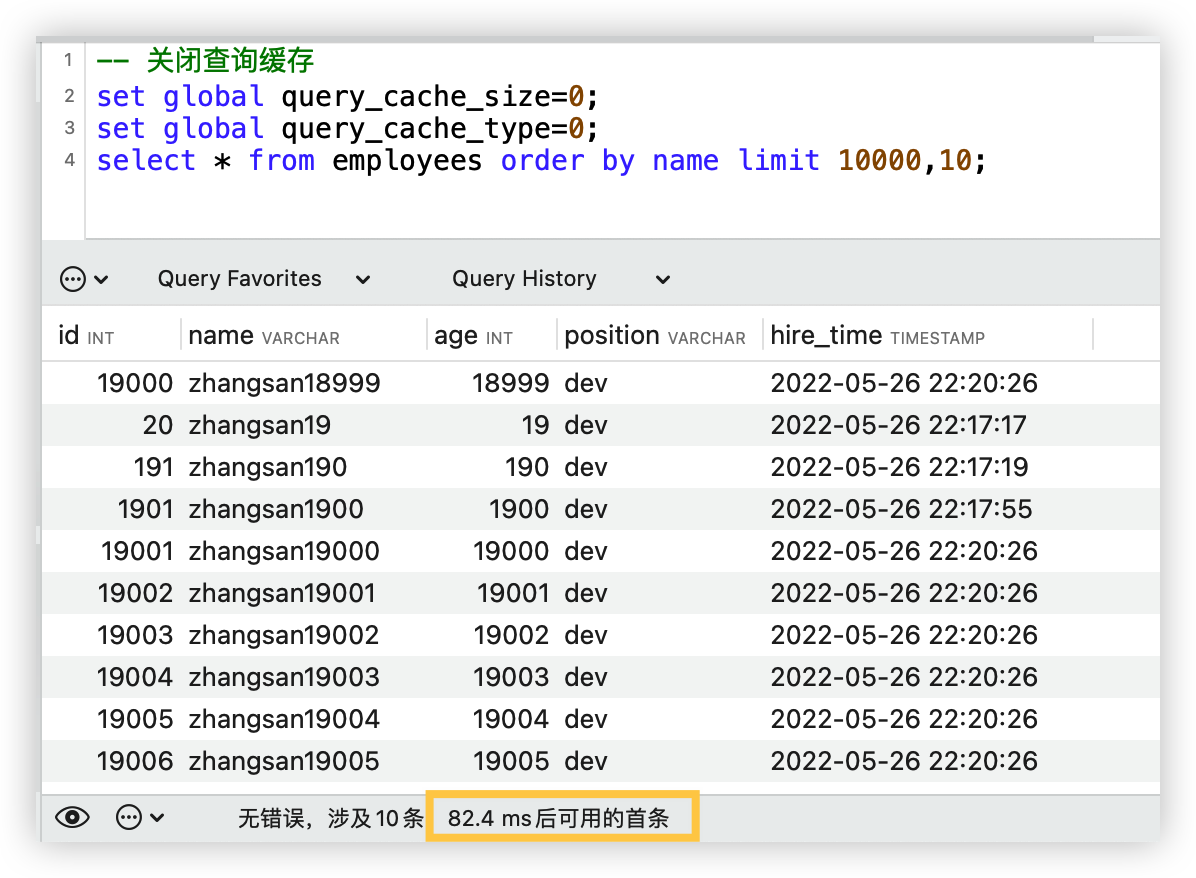
explain select * from employees order by name limit 10000,10;
这样的sql你会发现越翻到后面查询会越慢,这是因为这里看似是从表中查询10条记录,实际上是在表中查询了10010条记录,然后将10000条记录丢弃所得到的结果。
优化sql如下:
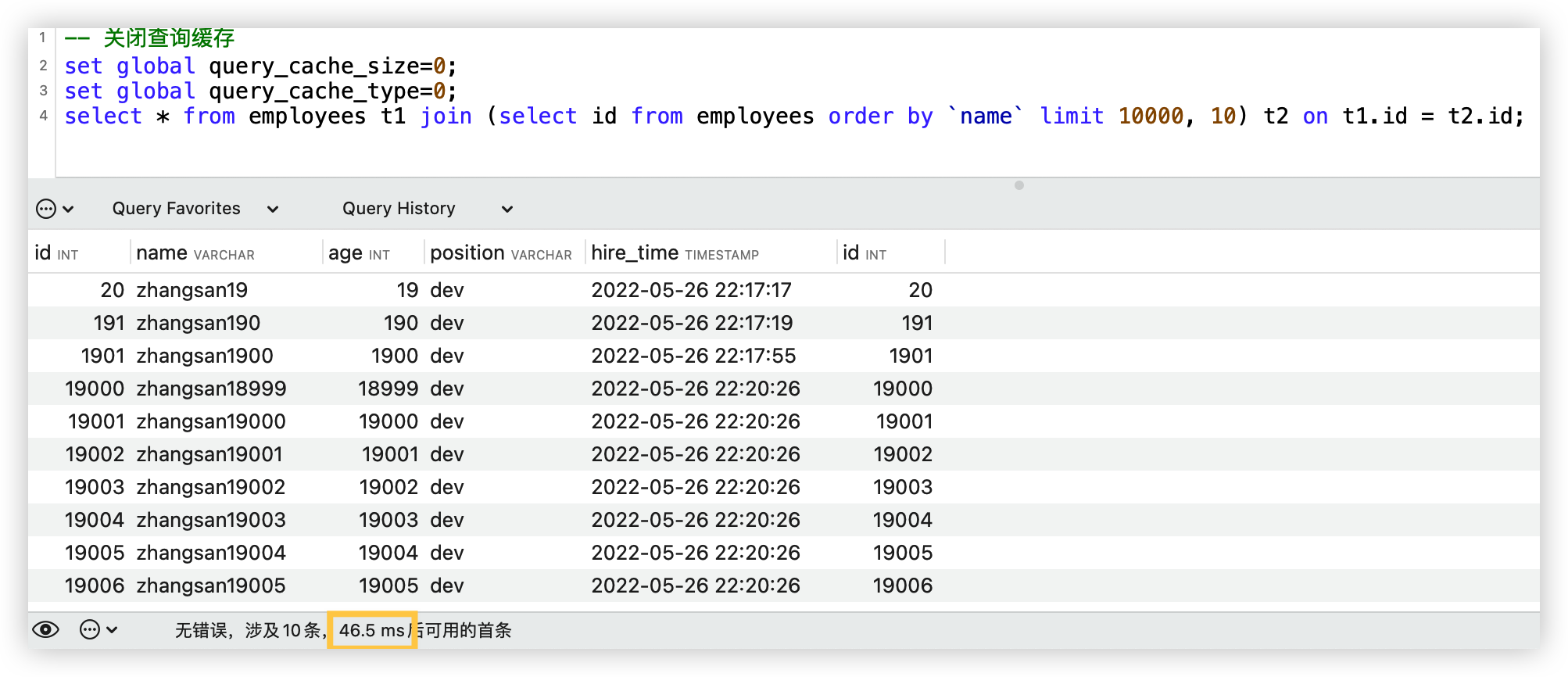
explain select * from employees t1 join (select id from employees order by `name` limit 10000, 10) t2 on t1.id = t2.id;
执行计划:

优化思路:先使用覆盖索引方式查出10条数据,再使用这10条数据连接查询。
覆盖索引:查询的字段被索引完全覆盖,比如id在联合索引中
原理:结合MySQL数据结构, 主键索引(innodb引擎)会存储完整的记录,而二级索引只存储主键。MySQL一个结点默认为16KB。
故:二级索引一个叶子结点能够存放的记录会多的多,扫描二级索引比扫描主键索引的IO次数会少很多。
图示:

优化前sql查询时间
set global query_cache_size=0;
set global query_cache_type=0;
优化后:
Join查询
jion查询分为内连接,左连接,右连接;
关联时又有两种情况:使用索引字段关联,不使用索引字段关联。
我以案例举例说明,如以下两张表t1,t2, a字段有索引,b字段无索引
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
t2表结构与t1完全相同
其中t1表具有1w条数据,t2表具有100条数据。
使用索引字段关联查询
explain select * from t1 inner join t2 on t1.a = t2.a;
执行计划:

分析执行计划:
1、先全表扫描t2表(100条数据)
2、使用t2表的a字段关联查询t1表,使用索引idx_a
3、取出t1表中满足条件的行,和t2表的数据合并,返回结果给客户端
成本计算:
1、扫描t2表:100次
2、扫描t1表:100次,因为使用索引可以定位出的数据,这个过程的时间复杂度大概是O(1)
此处说的100次只是为了更好的计算和理解,实际可能就几次
翻译成代码可能是这样:
for x in range(100): # 循环100次
print(x in t1) # 一次定位
所以总计扫描次数:100+100=200次
这里引出两个概念
小表驱动大表, 小表为驱动表,大表为被驱动表
inner join时,优化器一般会优先选择小表做驱动表, 排在前面的表并不一定就是驱动表。left join时,左表是驱动表,右表是被驱动表right join时,右表时驱动表,左表是被驱动表
嵌套循环连接 Nested-Loop Join(NLJ) 算法
一次一行循环地从第一张表(驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集。
使用索引字段关联查询的一般为NLJ算法
使用非索引字段查询
explain select * from t1 inner join t2 on t1.b = t2.b;
执行计划:

Extra列:Using join buffer:使用
join buffer(BNL算法)
分析执行计划:
1、先全表扫描t2表(100条数据),将数据加载到join buffer(内存)中
2、全表扫描t1表,逐一和join buffer中的数据比对
3、返回满足条件的行
成本计算:
1、扫描t2表:100次
2、扫描t1表:1w次
3、在内存中比对次数:100*10000=100w次
翻译成代码可能是这样:
for i in range(100): # 循环100次
for j in range(10000) # 循环10000次
所以总计扫描次数为:100+10000=10100次,内存中数据比对次数为:100*1w=100w次
这个过程称为:基于块的嵌套循环连接Block Nested-Loop Join(BNL)算法
把驱动表的数据读入到join buffer中,然后扫描被驱动表,把被驱动表每一行取出来跟join buffer中的数据做对比。
使用BNL算法join buffer不够时怎么办?
案例中t2表只有一百行数据,如果数据量很大时,比如t2表一共有1000行数据,join buffer一次只能放800行时怎么办?
此时会使用分段放的策略:先放入800行到join buffer,然后扫描t1表,比对完毕之后,将join buffer清空,放入剩余的200行,再次扫描t1表,再比对一次。
也就是说:此时会多扫描一次t1表,如果2次都放不下,就再多扫描一次,以此类推。
小结
join查询中一般有两种算法:
- 嵌套循环连接(NLJ)算法:使用索引字段关联查询
- 基于块的嵌套循环连接(BNL)算法:使用非索引字段关联查询
NLJ算法比BNL算法性能更高
关联查询的优化方式:
- 对关联字段加索引:让MySQL尽量选择NLJ算法
- 小表驱动大表:一般来说MySQL优化器会自己判断哪个是小表,如果使用
left join和right join是要注意。 - 如果不得已要使用BNL算法,那么在内存充足的情况下,可以调大一些
join buffer,避免多次扫描被驱动表。
为什么非索引字段不使用NLJ算法?
NLJ算法性能这么好,为什么非索引字段关联时不使用这种算法呢?
这是因为NLJ算法采用的是磁盘扫描方式:先扫驱动表,取出一行数据,通过该数据的关联字段到被驱动表中查找,这个过程是使用索引查找的,非常快。
如果非索引字段采用这种方式,那么通过驱动表的数据的关联字段,到被驱动表中查找时,由于无法使用索引,此时走的是全表扫描。
比如驱动表有100条数据,那么就要全表扫描被驱动表100次,被驱动表有1w条数据,那么就是磁盘IO:100*1w=100w次,这个过程是非常慢的。
In&Exist
in和exist的优化只有一个原则:小表驱动大表
in:当B表的数据集小于A表的数据集时,in优于exists
select * from A where id in (select id from B)
即in中的表为小表
exist: 当A表的数据集小于B表的数据集时,exists优于in
select * from A where exists (select 1 from B where B.id = A.id)
即外层的表为小表
count查询
关于count这里就不详细说明了,因为各种用法效率都差不多。
字段有索引:count(*)≈count(1)>count(字段)≈count(主键 id)
字段无索引:count(*)≈count(1)>count(主键 id)>count(字段)
索引设计原则
关于索引部分到这里就差不多了,总结一下索引设计原则
-
先写代码,再根据情况建索引
一般来说,都是都没代码写完之后,才能明确哪些字段会用到索引,但我也发现大部人写完代码就不管了。所以如果在设计时可以初步知道哪些字段可以建立索引,那么可以在设计表时就建好索引,写完代码再做调整
-
尽量让联合索引覆盖大部分业务
一个表不要建立太多的索引,因为MySQL维护索引也是需要耗费性能的,所以尽量让一到三个联合索引就覆盖业务里面的sql查询条件
-
不要在小基数的字段上建索引
如果在小基数的字段上建立索引是没有意义的,如性别,一张1千万数据的表,对半分的话500w男,500w女,筛选不出什么。
-
字符串长度过长的索引可以取部分前缀建立索引
字段过长的话也会导致索引占用的磁盘空间比较大,如varcahr(255), 这个时候可以取部分前缀建立索引,如前20个字符。但要注意的是,这样会导致排序失效,因为只取了前20个字符串,索引只能保证大范围的有序。
也可以在后期根据一定的计算规则计算最佳索引长度:distinct(left(字段,长度))/count约等于1
-
后期可以根据慢sql日志继续优化索引
随意业务的迭代,查询条件也会发生改变,此时可以根据慢sql持续优化索引
-
可以建唯一索引,尽量建唯一索引
-
where条件和order by冲突时时,优先取where的条件建索引
因为筛选出数据后,一般数据量比较少,排序的成本不大,所以优先让数据更快的筛选出来。